本篇文章基于:Xen Pv VPS,服务端Centos6 X86 32Bit系统, 客户端Windows系统,Xshell终端软件.
对于刚接触Linux系统的人会感觉一头雾水,有的同学甚至会尝试使用远程桌面去连接管理。
其实Linux入门非常简单的,首先。。。你要有一个可以用的服务器或者VPS,如果你没有的话可以去https://www.kvmla.com购买一个。
准备好ssh客户端工具 可以直接在这儿下载 http://down.kvm.la/windows/Xshell4.exe,安装Xshell选择Free for Home/School,可以免费使用无须破解。
ssh客户端建议使用原生的,破解软件和一些汉化软件有植入后门,我们提供的下载链接可以放心使用。
再次重复说一次开始:先去https://www.kvmla.com购买一个服务器或者VPS,Xen VPS效果最佳。
登陆会员中心
登陆会员中心就可以看到您的主机
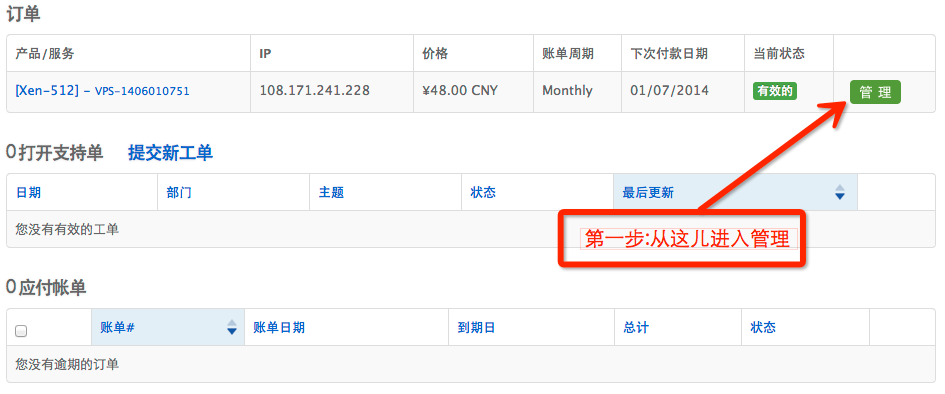
找到主机IP和密码
阅读剩余部分...
近期有同学要求开启vps的davfs2的支持,一下就一头雾水了, 然后花了一点时间把安装过程列了出来。
PS:下面过程是在Centos面进行操作
源码安装方式:首先需要安装编译环境gcc,然后是依赖环境neon,最后直接编译安装davfs.
yum -y --skip-broken install gcc gcc-c++ wget openssl-devel libxml2-devel
wget -c http://www.webdav.org/neon/neon-0.30.0.tar.gz
tar zxf neon-0.30.0.tar.gz
cd neon-0.30.0
./configure --with-ssl
make && make install
wget -c http://download.savannah.gnu.org/releases/davfs2/davfs2-1.5.0.tar.gz
tar zxf davfs2-1.5.0.tar.gz
cd davfs2-1.5.0
./configure --prefix=/
make && make install
useradd davfs2
二进制安装方式:
由于Centos的仓库没有davfs2所以借用强大的rpmforge第三方库安装davfs2
阅读剩余部分...
vesta面板基于LANMP环境,简洁开源非常不错,以下代码仅限Centos6有效
安装vesta
yum remove httpd* bind* -y
rm -rf /etc/httpd
curl -O http://vestacp.com/pub/vst-install.sh
bash vst-install.sh -f -n -e [email protected] #换成你的邮箱
安装设置suphp
阅读剩余部分...
最近发现DNS的53端口UDP攻击投诉特别多共同特点都是kloxo系统,
逐在google上搜索上发现了如下解决办法
rm -f /home/kloxo/httpd/default/*.php
sed -i 's/recursion yes/recursion no/g' /etc/named.conf
cat>> /var/named/chroot/etc/named.conf<<EOF
options {
recursion no;
};
EOF
/etc/init.d/named restart
/script/upcp
网上贴的解决办法需要动手几步,为了更懒更快解决就完善写成一次性复制粘贴搞定。
这两天莫名收到一堆网易的自动回复邮件,一开始还以为是被人轰炸了,在收到几封回复发现不大对劲.
这也不知道是谁这么恶心,基本症状是(随机发件人@kvm.la),随机标题,图片附件内容,然后批量发送到@163.com域。
Google apps方面的是将不存在账号邮件全部转发至一个账号处理不然也不会发现域名被人利用伪装发送邮件了。
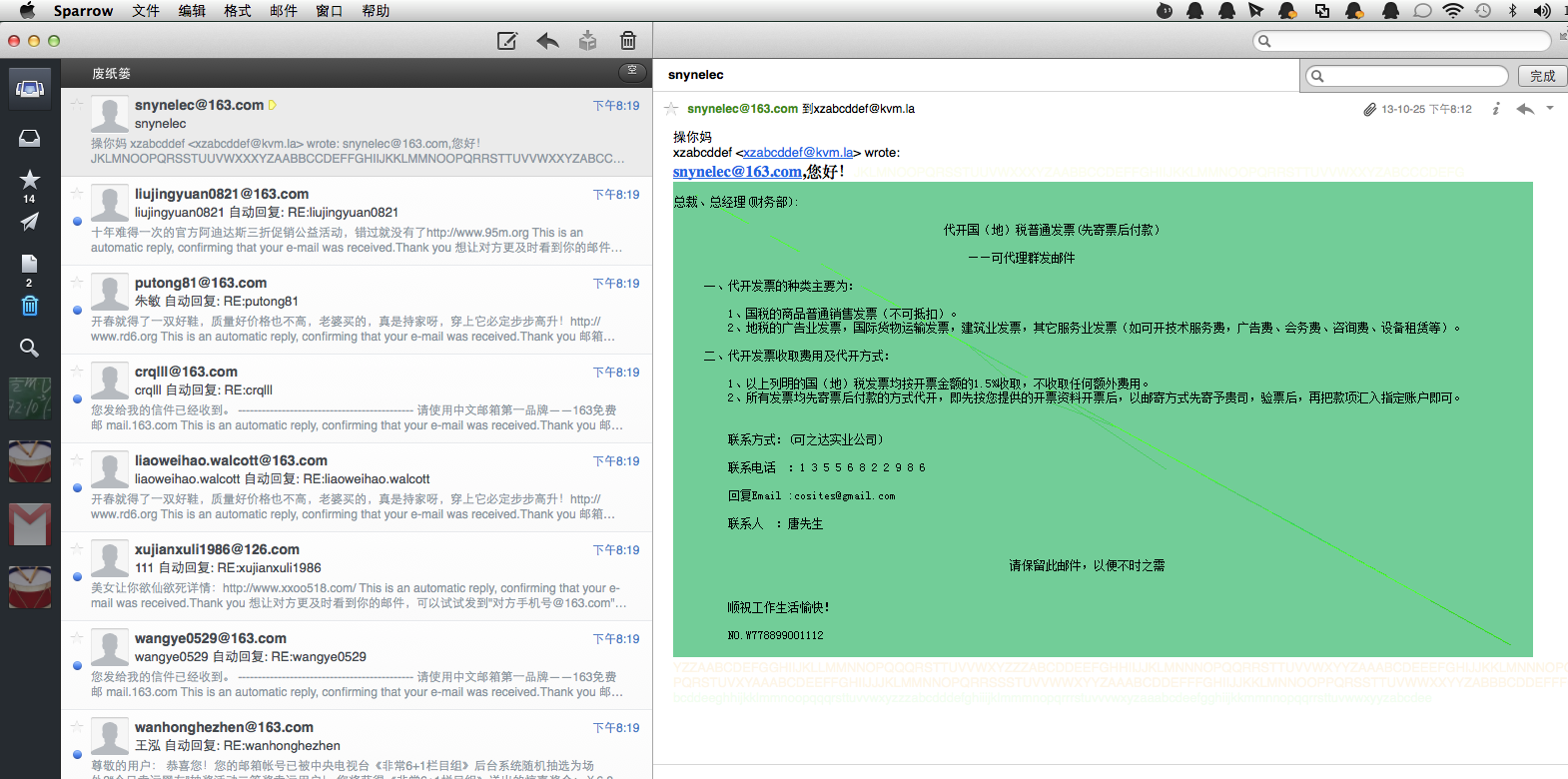
在折腾了半天后才联系上网易客服,先是一个man接的电话聊了半天完全是白搭。。。。。
然后再打了一次接电话的是一个妹子,最后得知确认发邮件到[email protected]然后等周一处理。
上次从HE.NET的DNS转出来后只做了A和MX记录,今晚登陆的时候才发现spf和DKIM的txt记录不在然后立马补上,希望网易的邮箱能认识spf吧。。。。。
附Google Apps的spf和DKIM设置:
spf>在域名内添加txt记录 名称:@ 值: v=spf1 include:_spf.google.com ~all
DKIM>在新版管理控制台中,点击 Google Apps > Gmail > 对电子邮件进行身份验证。
觉得DKIM设置不好找的话直接点击这儿的传送门https://admin.google.com/AdminHome?fral=1#AppDetails:service=email&flyout=dkim
Google官方FAQ原文地址
https://support.google.com/a/answer/178723
https://support.google.com/a/answer/174126
更新:
网易邮箱不认spf还是继续收信, 是伪造域发邮件的投递技术太强还是网易太弱。。。。
安装完Kloxo后有时候会发现ftp无法连接,检查安装包是安装上了的。
# rpm -qa|grep ftp
pure-ftpd-1.0.36-1.lxcenter
运行命令ps aux|grep ftp看不到ftp进程,如果FTP正常运行会看到如下类似的返回
阅读剩余部分...
2GMNX-8K7D2-X968C-7P62F-8B2QK
是标准版XC9B7-NBPP2-83J2H-RHMBY-92BT4
数据中心版48HP8-DN98B-MYWDG-T2DCC-8W83P
安装的时候需要用到 中文 英文都可以用 VL版尚未测试。
下载模块解压后用apxs进行安装
wget http://ivn.cl/files/source/mod_bw-0.92.tgz
tar zxvf mod_bw-0.92.tgz
apxs -c -i -a mod_bw.c
安装好后在对应的VirtualHost下加入下面代码
BandWidthModule On
ForceBandWidthModule On
BandWidth all 131072
BandWidth的单位:BandWidth [From] [bytes/s]
有时候会遇到这样的问题:df -h统计一个目录,显示有约100M可用空间,使用了5G;而用du -sh统计该目录下的文件大小,却发现总共才占用了1G。也就是说,二者统计结果差距巨大。
例如:
df-h /tmp/
结果:
3.9G 3.5G 220M 95% /tmp
du-sh /tmp/
结果:
132K /tmp/
结果差异巨大。
引用网上的一段话,原因是这样的:
(1)This section gives the technical explanation of why du and df sometimes report different totals of disk space usage.
When a program that is running in the background writes to a file while the process is running, the file to which this process is writing is deleted. Running df and du shows a discrepancy in the amount of disk space usage. The df command shows a higher value.
(2)The difference is that whenever an application has an open file, but the file is already deleted, then it is counted in the df output (because the space is certainly not free) but not in du (because it is not being used by a file).
如何查看是什么进程导致的问题?
假设你发现是 /tmp/ 目录不对劲,那么就这样就可以查看:
lsof| grep /tmp/
输出的结果中,注意某些含有“(deleted)”字样的记录,它们中的一部分就是罪魁祸首,将它们kill掉即可(如果可以重启这些进程所对应的服务的话,也有可能解决问题)。
上个月手淫同学给推荐安装office后可以顺带安装上远程桌面当时没当一回事丢脑后了,这几天遇上些问题不得不上服务器操作下就灰常土鳖的跑去下载了office才发现下了个更新包,
不经意搜索到原来微软有出OS X的远程桌面客户端,搜索到的是英文版顺藤摸瓜找到了中文版下载地址。
安装界面之许可协议
阅读剩余部分...
月初3号在serverhub上的服务器到今天22号中间各种曲折搞得非常不爽。
大致进程如下
3号下单付款然后再工单里面附上交易号客服非常快的回复并处理了账单;
阅读剩余部分...
有的时候一些程序比较挑php版本,一些稍微激进一点的程序都会对最新版本支持,如果嫌弃动手麻烦的话可以直接装个cpanel。
安装LAMP的环境配置大体流程如下
步骤一
首先必要条件安装好mysql和apache以及依赖环境包。
步骤二
安装php,5.2 5.3分开安装./configure的--prefix=路径分开指定成功编译完。
步骤三
前提说明mod_php模式有点戳上面安装php的时候记得fastcgi模式安装,如果是--with-apxs2参数安装的抱歉上去把参数调整好重新来过吧,到suphp官方下载编译安装好。
阅读剩余部分...
1.问题:小团队,快速迭代开发,版本发布没有经过测试就要放出去,怎样在内网测试过后在外网能在真实环境让内部人员再过一次测试且不影响外网用户
2.实现思想:
a.至少要有两台机器
b.公司是统一出口IP
c.根据IP将请求转发到不同的机器
阅读剩余部分...
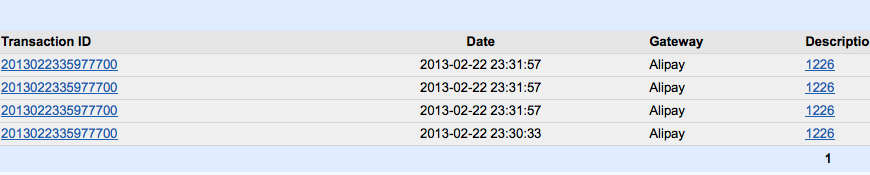
用户支付账单后会出现重复入账,少则一两次多则七八次。。。。
不排除支付宝跳转返回的时候用户F5刷新导致重复入账。。
附bug截图
运行“gpedit.msc”打开“组策略编辑器”
计算机配置 -> Windows 设置 -> 安全设置 -> 本地策略 -> 安全选项
“交互式登陆:不需要按 CTRL+ALT+DEL”改为“已启用”
显示“关闭事件跟踪程序”
计算机配置 ->管理模板 -> 系统
显示“关闭事件跟踪程序”改为“已禁用”
- «
- 1
- ...
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- ...
- 68
- »





