Rinetd是为在一个Unix和Linux操作系统中为重定向传输控制协议(TCP)连接的一个工具。Rinetd是单一过程的服务器,它处理任何数量的连接到在配置文件etc/rinetd中指定的地址/端口对。尽管rinetd使用非闭锁I/O运行作为一个单一过程,它可能重定向很多连接而不对这台机器增加额外的负担。
-----摘自百度百科
在内网里面我们可以使用iptables转发,但是在公网上面用Rinetd是不二的选择.
Rinetd不能像http里的$http_x_forwarded_for那样可以传递前端真实IP,在目标服务器上只能显示转发服务端的IP,如果是web服务可以用nginx来做反向代理。
Rinetd不能转发ftp,常规的3389 80 3306 1433这些端口服务都支持,在迁移数据中不能立即更换IP的时候在公网上转发数据大大的节省了很多不必要的麻烦。
安装方法:
阅读剩余部分...
登录系统ssh执行下面的命令
wget -c http://down.kvm.la/kloxo/kloxo_cn.tar.gz
tar zxf kloxo_cn.tar.gz -C /usr/local/lxlabs/kloxo/httpdocs/lang
最后在Appearance->Language里选择Chinese,然后点击update完成切换中文.
yum remove httpd -y
wget http://download.lxcenter.org/download/kloxo/production/kloxo-installer.sh
sh ./kloxo-installer.sh --type=master
首先猥琐的复制粘贴命令脚本,
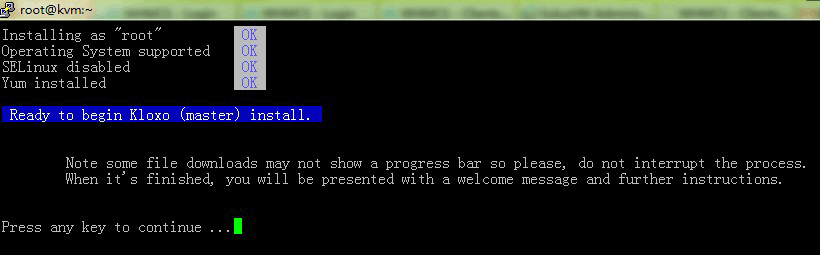
脚本运行后出现4个【OK】第一个为检查是否为root,第二个为检查是否系统支持(用debian/ubuntu类的同学请自重绕道),第三个为
阅读剩余部分...
针对整个mysql数据库进行全局热备份,恢复的时候可以覆盖恢复,恢复的时候必须是同版本,如果是迁移或者升级建议使用导出为sql文本.
在使用脚本的时候请定义root的密码
可以把脚本放入crond定时执行,对于已经存在的目录会自动重命名.
#!/bin/bash
PATH=/usr/local/sbin:/usr/bin:/bin
BACKDIR=/data/mysql_backup
ROOTUSER=youuser
ROOTPASS=youpassword
if [ -d $BACKDIR ]; then mv $BACKDIR $BACKDIR$(date +"-%Y-%m-%d-%H-%M-%S"); fi
mkdir -p $BACKDIR
for DATANAME in `ls -p /var/lib/mysql | grep / | tr -d /` ; do mysqlhotcopy $DATANAME -u $ROOTUSER -p $ROOTPASS $BACKDIR; done
在使用前请确认是否安装了perl-DBD
Centos/Redhat
yum install perl-DBD-mysql
debian/ubuntu
apt-get install libdbd-mysql-perl
美国凤凰城securedservers.com机房介绍
官方网址
http://www.securedservers.com/
测试下载文件
http://174.138.175.114/1gb-file.zip
securedservers机房位于美国亚利桑那州凤凰城市(也称菲利克斯)网络接入方面主要有Cogent和Level3(包含GBLX)
速度方面电信联通一直不错中规中矩不快也不慢比较稳定抽风是难免不了的偶尔来两下,总的来说可以入手,客服售后支持响应速度和处理问题都不错,需要代购可以联系本站。
机房已知IP段搜集列表
66.85.128.0/18
66.85.128.0/19
阅读剩余部分...
Ubiquity顾名思义无处不在,ubiquityservers.com在美国有七个数据中心非常强大。
优点机房多IP非常便宜一个C段255个IP 50美元每月
硬件上面稍贵
需要代购可以联系我们 邮件:
[email protected]
Atlanta, GA 佐治亚州 亚特兰大机房
Chicago, IL 伊利诺伊州 芝加哥机房
Dallas, TX 德克萨斯州 达拉斯机房
New York City, NY 纽约州 纽约机房
Phoenix, AZ 亚利桑那州 凤凰城机房 23.19.63.34
阅读剩余部分...
@echo off
set name=Cloud-%random%
reg add "HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\ComputerName\ActiveComputerName" /v ComputerName /t reg_sz /d %name% /f
reg add "HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\ComputerName\ComputerName" /v ComputerName /t reg_sz /d %name% /f
reg add "HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Tcpip\Parameters" /v "NV Hostname" /t reg_sz /d %name% /f
reg add "HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Tcpip\Parameters" /v Hostname /t reg_sz /d %name% /f
Clean.bat
@echo off
echo 正在清除系统垃圾文件,请稍候......
del /f /s /q %systemdrive%\*.tmp
del /f /s /q %systemdrive%\*._mp
del /f /s /q %systemdrive%\*.gid
del /f /s /q %systemdrive%\*.chk
del /f /s /q %systemdrive%\*.old
del /f /s /q %systemdrive%\recycled\*.*
del /f /s /q %windir%\*.bak
del /f /s /q %windir%\prefetch\*.*
rd /s /q %windir%\temp & md %windir%\temp
del /f /q %userprofile%\cookies\*.*
del /f /q %userprofile%\recent\*.*
del /f /s /q "%userprofile%\Local Settings\Temporary Internet Files\*.*"
del /f /s /q "%userprofile%\Local Settings\Temp\*.*"
del /f /s /q "%userprofile%\recent\*.*"
echo 清除工作完成!
echo. & pause
FTP协议有两种工作方式:PORT方式和PASV方式,中文意思为主动模式和被动模式
PORT(主动)方式的连接过程是:客户端向服务器的FTP端口(默认是21)发送连接请求,服务器接受连接,建立一条命令链路。当需要传送数据时,客户端在命令链路上用PORT 命令告诉服务器:“我打开了XXXX端口,你过来连接我”。于是服务器从20端口向客户端的 XXXX端口发送连接请求,建立一条数据链路来传送数据。
PASV(被动)方式的连接过程是:客户端向服务器的FTP端口(默认是21)发送连接请求,服务器接受连接,建立一条命令链路。当需要传送数据时,服务器在命令链路上用PASV 命令告诉客户端:“我打开了XXXX端口,你过来连接我”。于是客户端向服务器的XXXX端口 发送连接请求,建立一条数据链路来传送数据。
从上面可以看出,两种方式的命令链路连接方法是一样的,而数据链路的建立方法就完全不同,如下图:
一、FTP服务器的主动工作模式
二、FTP服务器的被动工作模式阅读剩余部分...
在nginx的配文件里面server段下面添加
rewrite /(plus|member|special|include|data|a|images|templets|uploads|dede)/(.*)\.(pl|php|cgi|asp|aspx|py|jsp) http://cachefly.cachefly.net/100mb.test redirect;
上面是用rewrite重定向的方法还有第二种方法用location
location ~(plus|member|special|include|data|a|images|templets|uploads|dede)/(.*)\.(pl|php|cgi|asp|aspx|py|tpl|jsp) {return 400;}
然后 reload或者restart一下nginx就可以了,上面的规则是直接给请求者返回一个100M的包,当然你也可以修改成其他的,详细用法参照http://wiki.nginx.org
service mysql restart --skip-grant-tables
mysql -u root -ppwd <<EOF
use mysql
update user set password=password("新密码") where user="root";
flush privileges;
EOF
service mysql restart
cat>/etc/init.d/sybased<<
#!/bin/bash
#
# chkconfig: 2345 81 31
# description: sybase start&stop script
# Source function library.
. /etc/rc.d/init.d/functions
SYB_OWNER=sybase
SYBASE=/opt/sybase
SYBASE_ASE=ASE-15_0
SYBASE_OCS=OCS-15_0
SYBASEDIR=\$SYBASE/\$SYBASE_ASE/install
SYB_STOP=\$SYBASE/\$SYBASE_OCS/bin
SAPASS=123456
DSQUERY=testb2bjoy
DATASERVER=testb2bjoy
RETVAL=0
PATH=\$SYBASE/\$SYBASE_ASE/bin:/\$SYBASE/\$SYBASE_ASE/install:/\$SYBASE/\$SYBASE_OCS/binPATHHOME/bin:/etc:/usr/sbin:/usr/ucb:/usr/bin/X11:/bin:.
export SYBASE DSQUERY SYBASE_ASE SYBASE_OCS DATASERVER SYBASEDIR PATH
if [ ! -f \$SYBASE/\$SYBASE_ASE/install/startserver ]
then
echo "Sybase startup: startserver not found"
exit
fi
start()
{
su - \$SYB_OWNER -c "\$SYBASE/\$SYBASE_ASE/install/startserver -f \$SYBASEDIR/RUN_"\$DATASERVER""
sleep 60
su - \$SYB_OWNER -c "\$SYBASE/\$SYBASE_ASE/install/startserver -f \$SYBASEDIR/RUN_"\$DATASERVER"_bs"
RETVAL=\$?
if [ \$RETVAL -eq 0 ]; then
action \$"Starting Sybase 12.5 startserver: " /bin/true
else
action \$"Starting Sybase 12.5 startserver: " /bin/false
fi
return \$RETVAL
}
stop()
{
su - \$SYB_OWNER -c "isql -Usa -P\$SAPASS -S\$DATASERVER -i\$SYBASE/\$SYBASE_ASE/install/shutdown_backup.sql"
su - \$SYB_OWNER -c "isql -Usa -P\$SAPASS -S\$DATASERVER -i\$SYBASE/\$SYBASE_ASE/install/shutdown_dataserver.sql"
RETVAL=\$?
if [ \$RETVAL -eq 0 ]; then
action \$"Stopping Sybase 12.5 sybshutdown: " /bin/true
else
action \$"Stopping Sybase 12.5 sybshutdown: " /bin/false
RETVAL=1
fi
return \$RETVAL
}
restart()
{
stop
start
}
pid="dataserver"
case "\$1" in
start)
start
RETVAL=\$?
;;
stop)
stop
RETVAL=\$?
;;
status)
su - sybase -c "/opt/sybase/ASE-15_0/install/showserver"
RETVAL=\$?
;;
restart)
restart
RETVAL=\$?
;;
*)
echo \$"Usage: \$0 {start|status|stop|restart}"
exit 1
esac
exit \$RETVAL
EOF
chmod 755 /etc/init.d/sybased
chkconfig add sybased
chkconfig --list |grep sybased
[root@host1 src]# wget ftp://ftp.gnu.org/pub/gnu/screen/screen-4.0.3.tar.gz
[root@host1 src]# tar -xvf screen-4.0.3.tar.gz
[root@host1 src]# cd screen-4.0.3
[root@host1 screen-4.0.2]# ./configure
[root@host1 screen-4.0.2]# make
[root@host1 screen-4.0.2]# make install
[root@host1 screen-4.0.2]# install -m 644 etc/etcscreenrc /etc/screenrc
[root@host1 screen-4.0.2]# cp ./screen /bin
注意和一般程序的安装过程有所不同,后面这两条指令一定要执行。
如题,今天用yum安装软件的时候一直提示这个,不管安装什么软件包都这样,后google之,执行以下命令即可解决:
yum install glibc glibc.i386 –enablerepo=c532*
很多人习惯了win上的操作,点点鼠标就能完成工作,面对linux上的那么多操作命令,素手无策,今天我给大家分享一款图形化系统管理工具软件Webmin
Webmin是目前功能最强大的基于Web的Unix系统管理工具。管理员通过浏览器 访问Webmin的各种管理功能并完成相应的管理动作。目前Webmin支持绝大多数的Unix系统,这些系统除了各种版本的linux以外还包括:AIX、HPUX、Solaris、Unixware、Irix和FreeBSD等。
Webmin 让您能够在远程使用支持HTTPS (SSL 上的 HTTP)协议的 Web 浏览器通过 Web 界面管理您的主机。这在保证了安全性的前提下提供了简单深入的远程管理。这使得 Webmin 对系统管理员非常理想,因为所有主流平台都有满足甚至超出上述需求的 Web 浏览器。而且,Webmin 有其自己的“Web 服务器”,因此不需要运行第三方web软件(比如apache服务器或nginx服务器)。万事具备。Webmin 的模块化架构允许您在需要时编写您自己的配置模块。除了在此介绍的模块之外,Webmin 还包括许多模块。尽管目前我们将主要关注网络服务,但是您会看到,几乎您系统的每一部分都能够通过 Webmin 来配置和管理。
1、用ssh客户端软件登陆服务器
2、用root切换目录到/opt下,命令是:cd /opt
3、下载Webmin的安装文件,命令是:wget http://prdownloads.sourceforge.net/webadmin/webmin-1.450.tar.gz
4、解压缩文件,命令是:tar -xzf webmin-1.450.tar.gz
5、进入webmin的解压缩目录,然后运行setup.sh,命令为:./setup.sh
6、一路回车即可安装完成,最后有一个地方需要设置用户名和密码的地方,用户名默认是admin,可以自己修改,密码输入2次即可
详细操作如下:
Config file directory[/etc/webmin]: 回车 //直接回车表示选择默认安装路径,也可下其它路径,然后接回车键
Log file directory[/var/webmin]: 回车 //同上
Web server port (default 10000):回车 //指定Web访问的端口,默认端口为10000
Login name (default admin)://在这里输入登录用户名,默认是“admin”
Login password: 输入密码
Password again: 再次输入密码
Start Webmin at boot time (y/n):输入”y”
7、等看到安装完成的提示之后,在浏览器中输入http://ip:10000或 http://localhost:10000/ ,然后回车,如果看到一个登陆界面,就说明webmin已经安装成功了。至此表明,安装在Linux系统下的Webmin可以正常工作了。正确输入用户名及口令(默认只有admin账号可以登陆),就可以对系统管理了。
8、刚安装时是英文界面,登录webmin系统后,依次打开Webmin →Webmin Configuration →Language,在 Display in Language处选择Simplified Chinese (ZH_CN),然后再点击”Change Language”重新进入webmin系统时就会显示中文了。
安装成功的童鞋们,你们觉得好用吗?
- «
- 1
- ...
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- ...
- 68
- »





