grep / egrep
笔者在前面的内容中多次提到并用到grep命令,可见它的重要性。所以好好学习一下这个重要的命令吧。你要知道的是grep连同下面讲的sed, awk都是针对文本的行才操作的。
语法: grep [-cinvABC] ‘word’ filename
-c :打印符合要求的行数
-i :忽略大小写
-n :在输出符合要求的行的同时连同行号一起输出
-v :打印不符合要求的行
-A :后跟一个数字(有无空格都可以),例如 –A2则表示打印符合要求的行以及下面两行
-B :后跟一个数字,例如 –B2 则表示打印符合要求的行以及上面两行
-C :后跟一个数字,例如 –C2 则表示打印符合要求的行以及上下各两行
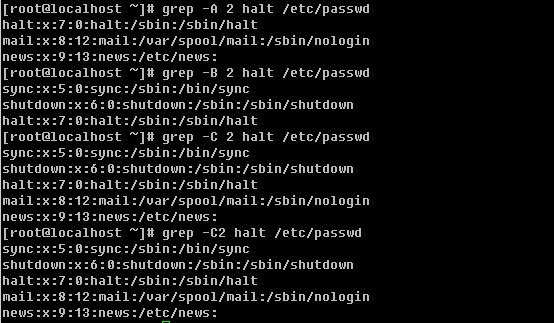
以下,笔者举几个小例子帮助你好好掌握这个grep工具的用法。
a. 过滤出带有某个关键词的行并输出行号

b. 过滤不带有某个关键词的行,并输出行号
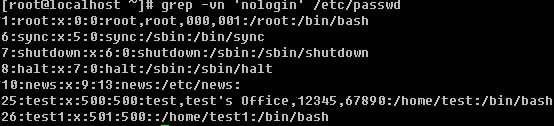
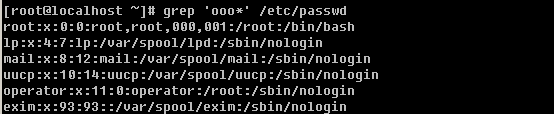
c. 过滤出所有包含数字的行
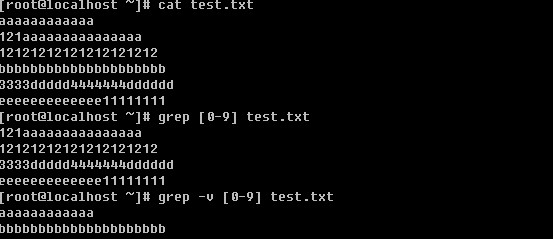
在前面也提到过这个”[ ]”的应用,如果是数字的话就用[0-9]这样的形式,当然有时候也可以用这样的形式[15]即只含有1或者5,注意,它不会认为是15。如果要过滤出数字以及大小写字母则要这样写[0-9a-zA-Z]。另外[ ]还有一种形式,就是[^字符] 表示除[ ]内的字符之外的字符。

这就表示筛选包含oo字符串,但是不包含r字符。
d. 过滤出文档中以某个字符开头或者以某个字符结尾的行
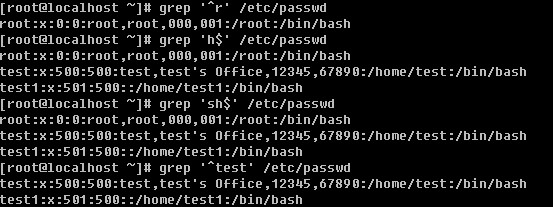
在正则表达式中,”^”表示行的开始,”$”表示行的结尾,那么空行则表示”^$”,如果你只想筛选出非空行,则可以使用 “grep -v ‘^$’ filename”得到你想要的结果。现在想一下,如何打印出不以英文字母开头的行呢?
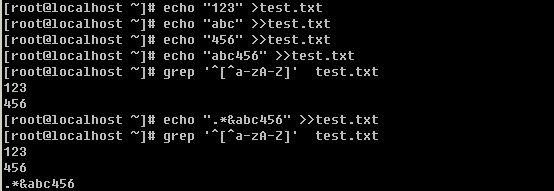
e. 过滤任意一个字符与重复字符

“.”表示任意一个字符,上例中,就是把符合r与o之间有两个任意字符的行过滤出来。
“*”表示零个或多个前面的字符。
‘ooo*’ 表示oo, ooo, oooo … 或者更多的’o’。现在你是否想到了’.*’ 这个组合表示什么意义?

‘.*’表示零个或多个任意字符,空行也包含在内。
f. 指定要过滤字符出现的次数

这里用到了{ },其内部为数字,表示前面的字符要重复的次数。上例中表示包含有两个o 即’oo’的行。注意,{ }左右都需要加上脱意字符’\’。另外,使用{ }我们还可以表示一个范围的,具体格式是 ‘\{n1,n2\}’其中n1<n2,表示重复n1到n2次前面的字符,n2还可以为空,则表示大于等于n1次。
上面部分讲的grep,另外笔者常常用到egrep这个工具,简单点讲,后者是前者的扩展版本,我们可以用egrep完成grep不能完成的工作,当然了grep能完成的egrep完全可以完成。如果你嫌麻烦,egrep了解一下即可,因为grep的功能已经足够可以胜任你的日常工作了。下面笔者介绍egrep不用于grep的几个用法。为了试验方便,笔者把test.txt 编辑成如下内容:
rot:x:0:0:/rot:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
operator:x:11:0:operator:/rooot:/sbin/nologin
roooot:x:0:0:/rooooot:/bin/bash
1111111111111111111111111111111
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
a. 筛选一个或一个以上前面的字符
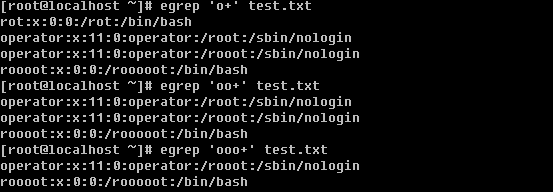
和grep 不同的是,egrep这里是使用’+’的。
b. 筛选零个或一个前面的字符
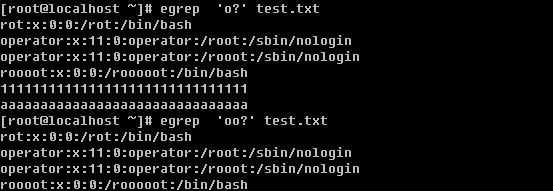
c. 筛选字符串1或者字符串2

中间有一个’|’表示或者的意思,笔者用这个用的很多,所以这个你最好记一下。
d. egrep中’( )’的应用

用’( )’表示一个整体,例如(oo)+就表示1个’oo’或者多个’oo’

语法: grep [-cinvABC] ‘word’ filename
-c :打印符合要求的行数
-i :忽略大小写
-n :在输出符合要求的行的同时连同行号一起输出
-v :打印不符合要求的行
-A :后跟一个数字(有无空格都可以),例如 –A2则表示打印符合要求的行以及下面两行
-B :后跟一个数字,例如 –B2 则表示打印符合要求的行以及上面两行
-C :后跟一个数字,例如 –C2 则表示打印符合要求的行以及上下各两行
以下,笔者举几个小例子帮助你好好掌握这个grep工具的用法。
a. 过滤出带有某个关键词的行并输出行号
b. 过滤不带有某个关键词的行,并输出行号
c. 过滤出所有包含数字的行
在前面也提到过这个”[ ]”的应用,如果是数字的话就用[0-9]这样的形式,当然有时候也可以用这样的形式[15]即只含有1或者5,注意,它不会认为是15。如果要过滤出数字以及大小写字母则要这样写[0-9a-zA-Z]。另外[ ]还有一种形式,就是[^字符] 表示除[ ]内的字符之外的字符。
这就表示筛选包含oo字符串,但是不包含r字符。
d. 过滤出文档中以某个字符开头或者以某个字符结尾的行
在正则表达式中,”^”表示行的开始,”$”表示行的结尾,那么空行则表示”^$”,如果你只想筛选出非空行,则可以使用 “grep -v ‘^$’ filename”得到你想要的结果。现在想一下,如何打印出不以英文字母开头的行呢?
e. 过滤任意一个字符与重复字符
“.”表示任意一个字符,上例中,就是把符合r与o之间有两个任意字符的行过滤出来。
“*”表示零个或多个前面的字符。
‘ooo*’ 表示oo, ooo, oooo … 或者更多的’o’。现在你是否想到了’.*’ 这个组合表示什么意义?
‘.*’表示零个或多个任意字符,空行也包含在内。
f. 指定要过滤字符出现的次数
这里用到了{ },其内部为数字,表示前面的字符要重复的次数。上例中表示包含有两个o 即’oo’的行。注意,{ }左右都需要加上脱意字符’\’。另外,使用{ }我们还可以表示一个范围的,具体格式是 ‘\{n1,n2\}’其中n1<n2,表示重复n1到n2次前面的字符,n2还可以为空,则表示大于等于n1次。
上面部分讲的grep,另外笔者常常用到egrep这个工具,简单点讲,后者是前者的扩展版本,我们可以用egrep完成grep不能完成的工作,当然了grep能完成的egrep完全可以完成。如果你嫌麻烦,egrep了解一下即可,因为grep的功能已经足够可以胜任你的日常工作了。下面笔者介绍egrep不用于grep的几个用法。为了试验方便,笔者把test.txt 编辑成如下内容:
rot:x:0:0:/rot:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
operator:x:11:0:operator:/rooot:/sbin/nologin
roooot:x:0:0:/rooooot:/bin/bash
1111111111111111111111111111111
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
a. 筛选一个或一个以上前面的字符
和grep 不同的是,egrep这里是使用’+’的。
b. 筛选零个或一个前面的字符
c. 筛选字符串1或者字符串2
中间有一个’|’表示或者的意思,笔者用这个用的很多,所以这个你最好记一下。
d. egrep中’( )’的应用
用’( )’表示一个整体,例如(oo)+就表示1个’oo’或者多个’oo’
none





