在一台DELL R310的宿主机上安装了Ubuntu Server 12.10默认集成KVM虚拟机,用户态虚拟机软件qemu-kvm使用seabios的作为bios实现(位于 /usr/share/qemu-kvm/bios.bin,来自于qemu-common 1.2.0+noroms-0ubuntu2),该bios.bin仅包含部分来自宿主机的SLIC信息,但不完整,无法通过Window OEM验证。
本文将介绍安装KVM虚拟机,借助virt-install安装Windows客户机,去除bios.bin里内置的SLIC,然后使用-acpitable参数载入正确的SLIc 2.1信息,导入OEM证书和OEM key激活Windows。
由于Ubuntu Server没有安装图形环境,DELL R310服务器也是不带显示器的,所有windows的安装过程是通过本来的Macbook Air的VNC客户端操作的。
安装KVM虚拟机
首先检查你的处理器是否支持硬件虚拟化;如果支持,下面这个命令
$ sudo egrep '(vmx|svm)' --color=always /proc/cpuinfo
会看到如下类似信息
阅读剩余部分...
直接生成的配置文件启动的guest os会显示QEMU Virtual CPU, 其实老早就想写了 人又太懒了,最近调试Kvm又用上了就记录一下
<domain type='kvm' >
to
<domain type='kvm' xmlns:qemu='http://libvirt.org/schemas/domain/qemu/1.0'>
<qemu:commandline>
<qemu:arg value='-cpu'/>
<qemu:arg value='host'/>
</qemu:commandline>
一般用模板安装后C盘算固定的定制大小,或者要么就是一个硬盘就一个C盘.
这里主要说一下如何启用未划分的磁盘
具体流程 我的电脑属性>计算机管理>存储>磁盘管理>分配盘符
其他乱七八糟的就不叙述了,请直接看图片
阅读剩余部分...
安装Xen和Kvm的时候brctl show会看到virbr0的网卡 直接删除又删不掉.
Kvm直接建立网桥配置倒是没什么影响,Xen下不是走peth0的话guest os就没办法上网,
综合一下 这个对咋们错杀一千也绝对不能留下来.
直接用brctl delbr virbr0会提示使用中无法删除,所以让ifconfig停掉它
实例命令
ifconfig virbr0 down
brctl delbr virbr0
命令CTRL+Z强制将当前进程转为后台,并使之停止。
1、使进程恢复运行(后台)
使用命令bg
$bg
如果用CTRL+Z停止了几个程序,可用命令$jobs查看
如[1]- Running ./test1 &
[2]+Stopped ./test2
可使用命令$bg %1 将任务1转入后台运行
2、使进程恢复至前台运行
命令$fg
总结:
阅读剩余部分...
kvmla测试kvm虚拟化有一个多月了,现在已经开始公测了. 这里记录一下virsh管理下的kvm配置文件实例大全
<domain type='vbox'>
<name>vbox</name>
<uuid>4dab22b31d52d8f32516782e98ab3fa0</uuid>
<os>
<type>hvm</type>
<boot dev='cdrom'/>
<boot dev='hd'/>
<boot dev='fd'/>
<boot dev='network'/>
</os>
<memory>654321</memory>
<vcpu>1</vcpu>
阅读剩余部分...
凌动 ATOMD510 1.66GHZ 2GB内存 160GB SATA硬盘 10TB 流量 100 Mbps 3IP $64.95/月
双核E7400 2.83GHz 2GB内存 160GB SATA硬盘 10TB 流量 100 Mbps 3IP $69.95/月
双核E5200 2.5GHz 2GB内存 320GB SATA硬盘 10TB 流量 100 Mbps 3IP $64.95/月
Krypt 机房和电信联通直连 速度非常不错
没事干在nginx的default站点下添加段listen 443;默认监听443, 没想到原来一直正常的https站全部打不开了.
SSL 接收到一个超出最大准许长度的记录。
(错误码: ssl_error_rx_record_too_long)
去掉后解决了冲突..............
在业界,一直流传这样一句话:Nginx抗并发能力强!为什么Nginx抗并发能力强?原因是使用了非阻塞、异步传输
阻塞:如apache代理tomcat时,apache开启10个进程,同时处理着10个请求,在tomcat没有返回给apache结果时,apache是不会处理用户发出的第11个请求
非阻塞:如nginx代理tomcat时,nginx开启1000个并发,同时处理着1000个请求,在tomcat没有返回给nginx结果时,nginx会依然处理后面用户发给的请求
同步传输:比如squid代理tomcat时,浏览器发起请求,然后请求会squid立刻被转到后端服务器,于是在浏览器和后端服务器之间就建立了一个连接。在请求发起到请求完成,这条连接都是一直存在的。
异步传输:比如nginx代理tomcat时,浏览器发起请求,请求不会立刻转到后端服务器,而是将请求数据(header)先保存到nginx上,然后nginx再把这个请求发到后端服务器, 后端服务器处理完之后把数据返回到nginx上,nginx将数据流发到浏览器。
如上图所示假设用户执行一个上传文件操作,由于用户网速较慢,因此需要花半个小时才能把文件传到服务器。squid的同步代理在用户开始上传后就和
后端tomcat建立了连接,半小时后文件上传结束,所以,后端tomcat服务器连接保持了半个小时;而nginx异步代理就是先将数据保存在
nginx上,因此仅仅是nginx和用户
保持了半小时连接,后端服务器在这半小时内没有为这个请求开启连接,半小时后用户上传结束,nginx才将上传内容发到后端tomcat,nginx和后
台之间的带宽 是很充裕的,所以只花了一秒钟就将请求发送到了后台,由此可见,后端服务器连接保持了一秒。
阅读剩余部分...
编译安装xen成功启动后 发现小鸡启动有些问题,启动卡住半天跳出
Error: Device 0 (vif) could not be connected. Hotplug scripts not working.
回想起编译内核 应该是有东西没编译进去.
cat .config|grep CONFIG_XEN_NETDEV_BACKEND
#CONFIG_XEN_NETDEV_BACKEND is not set
查找发现是netdev backend没启用
改为CONFIG_XEN_NETDEV_BACKEND=y然后grep XEN看下其他还有什么选择
果断全部开启 然后重新编译内核
最后 记得修改grub启动项
centos5.6 kernel版本:2.6.18-238.el5-i686
所编译的kernel版本:linux-3.6.4.tar.bz2
1.将新内核cp到/usr/src目录下,然后释放内核源代码:
#bzip2 -d linux-3.6.4.tar.bz2 -> linux-3.6.4.tar
#tar -xvf linux-3.6.4.tar
2.开始设置内核编译模块及参数
make menuconfig
设置编译成模块或是否编译进内核或不选,这里增加了新内核对于虚拟化的支持模块,其他保持不变,保存退出。
make mrproper or make clean
删除安装过程中产生的大量临时文件
注意:如果直接跳过下面步骤,在make bzImage过程中会报以下错误:
阅读剩余部分...
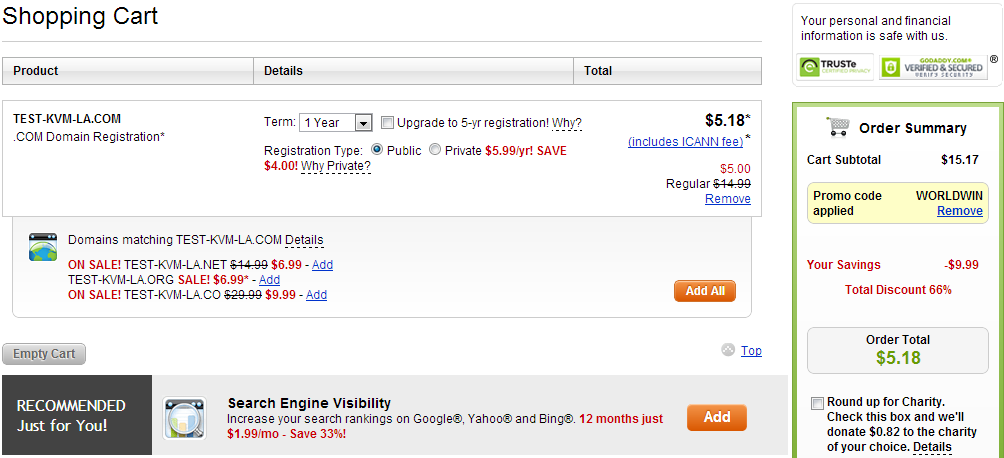
Godaddy已经被强大的国人搞残了,一刀两刀的日子不复存在,大家就不要想着如何卡油占便宜了.
注册链接:
http://www.godaddy.com/?isc=WORLDWIN
只能注册一个com享有49%的优惠,但是测试验证转入一个net域名也能同时获得49%的优惠.
优惠码到期时间为 美国时间 11月30号.
系统需求
首先确定操作系统环境,不建议在 Windows 上面搞,所以你需要用:
- Mac OS X
- 任意 Linux 发行版本(Ubuntu,CentOS, Redhat, ArchLinux ...)
强烈新手使用 Ubuntu 省掉不必要的麻烦!
以下代码区域,带有 $ 打头的表示需要在控制台(终端)下面执行(不包括 $ 符号)
步骤0 - 安装系统需要的包
- Mac 请安装 Xcode 开发工具,它将帮你安装好 Unix 环境需要的开发包
- Ubuntu 请安装
阅读剩余部分...
inode中文意思索引节点,这里主要说一下ext3分区调整磁盘的inode number。
#首先调整inodes的分区或者文件要处于空闲状态.
# mkfs.ext3 /dev/vg0/templvm -N "inode节点数"
# mkfs.ext3 命令的-N 选项用于指定自定义的inode节点数
#挂载分区
# mout /dev/vg0/templvm /mnt
#查看修改后的inode参数
# df -i
个人平常用LVM分区,很少用单个文件做磁盘存储,不过大体操作都一样,/dev/vg0/templvm替换成你的硬盘分区或者文件路径。
特别注意:调整inode是用mkfs.ext3带上参数格式化分区,在操作前一定要记得打包备份数据,格式化数据后LVM快照的方式备份也会I/O错误。
作为kvmla管理团队一员 我认为这篇文章还是值得转载一下的
事件起因原由大致如下:
前因
一网友在kvmla网购一个256M内存月付36元的vps,由于价格定位是无管理型VPS(也就是说只要vps正常运行可以正常进行管理,技术人员是不提供技术支持的),所以在tickt上回复让其自行检查处理。
其后收到退款请求,原则上按照TOS服务条款我们三天无条件退款,但在低价促销中夹杂着一些高风险用户,所以不论使用了多久,执意要退款者我们也不会推三阻四或刻意为难.
该网友是在2012-10-15 21:21提交退款申请,系统每天凌晨12点会自动处理 暂停 删除一切自动化进程.
事件澄清
第一点:非管理型vps不提供额外的技术支持,例如需要安装或者调整gcc php mysql apache ftp pptp;但是一些例如系统无法开机,IP冲突或者受到CC攻击需要协助,这些是份内援助的,
第二点: 在提交退款申请以前个人应该做好备份备份处理,除非你的数据是没有任何价值的, 作为服务商没有义务做用户备份和保留终止服务的数据。
工单完整细节
阅读剩余部分...
- «
- 1
- ...
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- ...
- 68
- »





