本帖最后由 andy 于 2010-2-10 10:15 编辑
说明: 此脚本完全转自网络,感觉脚本写的十分不错,故转过来收藏。
#!/bin/sh
# this shell script finds all the tables for a database and run a command against it
# @usage "mysql_table_optimize.sh --optimize MyDatabaseABC"
# @date 8/1/2008
# @base on author Son Nguyen's script mysql_tables.sh chaged by
[email protected]
DBNAME=$2
printUsage() {
echo "Usage: $0"
echo " --optimize <dbname>"
echo " --repair <dbname>"
return
}
doAllTables() {
#### Get user account for mysql
echo -n "Enter you mysql user name here:"
read User;
echo -n "Enter you passwd for mysql $User:"
read -s PASSWD;
#### Get all table name and then oprate them with "'$DBCMD' tables"
mysql ${DBNAME} -u$User -p${PASSWD} -e "show tables;" |grep -v "Tables_in_" | \
awk '{print "'$DBCMD' table '$DBNAME'." $1 ";"}' | \
xargs -i mysql -u$User -p${PASSWD} -e {};
}
if [ $# -eq 0 ] ; then
printUsage
exit 1
fi
case $1 in
--optimize) DBCMD=OPTIMIZE; doAllTables;;
--repair) DBCMD=REPAIR; doAllTables;;
--help) printUsage; exit 1;;
*) printUsage; exit 1;;
esac
Mysql的复制可以是基于一条语句(Statement level),也可以是基于一条记录(Row level),可以在Mysql的配置参数中设定这个复制级别,不同复制级别的设置会影响到Master端的bin-log记录成不同的形式。
Row Level:日志中会记录成每一行数据被修改的形式,然后在slave端再对相同的数据进行修改。
优点:在row level模式下,bin-log中可以不记录执行的sql语句的上下文相关的信息,仅仅只需要记录那一条记录被修改了,修改成什么样了。所以row level的日志内容会非常清楚的记录下每一行数据修改的细节,非常容易理解。而且不会出现某些特定情况下的存储过程,或function,以及 trigger的调用和触发无法被正确复制的问题。
缺点:row level下,所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容,比如有这样一条update语句:update product set owner_member_id = ‘b’ where owner_member_id = ‘a’,执行之后,日志中记录的不是这条update语句所对应额事件(mysql以事件的形式来记录bin-log日志),而是这条语句所更新的每一条记录的变化情况,这样就记录成很多条记录被更新的很多个事件。自然,bin-log日志的量就会很大。尤其是当执行alter table之类的语句的时候,产生的日志量是惊人的。因为Mysql对于alter table之类的表结构变更语句的处理方式是整个表的每一条记录都需要变动,实际上就是重建了整个表。那么该表的每一条记录都会被记录到日志中。
Statement Level:每一条会修改数据的sql都会记录到 master的bin-log中。slave在复制的时候sql进程会解析成和原来master端执行过的相同的sql来再次执行。
优点:statement level下的优点首先就是解决了row level下的缺点,不需要记录每一行数据的变化,减少bin-log日志量,节约IO,提高性能。因为他只需要记录在Master上所执行的语句的细节,以及执行语句时候的上下文的信息。
缺点:由于他是记录的执行语句,所以,为了让这些语句在slave端也能正确执行,那么他还必须记录每条语句在执行的时候的一些相关信息,也就是上下文信息,以保证所有语句在slave端杯执行的时候能够得到和在master端执行时候相同的结果。另外就是,由于Mysql现在发展比较快,很多的新功能不断的加入,使mysql得复制遇到了不小的挑战,自然复制的时候涉及到越复杂的内容,bug也就越容易出现。在statement level下,目前已经发现的就有不少情况会造成mysql的复制出现问题,主要是修改数据的时候使用了某些特定的函数或者功能的时候会出现,比如:sleep()函数在有些版本中就不能真确复制,在存储过程中使用了last_insert_id()函数,可能会使slave和master上得到不一致的id等等。由于row level是基于每一行来记录的变化,所以不会出现类似的问题。
从官方文档中看到,之前的Mysql一直都只有基于statement的复制模式,直到5.1.5版本的Mysql才开始支持row level的复制。从5.0开始,Mysql的复制已经解决了大量老版本中出现的无法正确复制的问题。但是由于存储过程的出现,给Mysql的复制又带来了更大的新挑战。另外,看到官方文档说,从5.1.8版本开始,Mysql提供了除Statement Level和Row Level之外的第三种复制模式:Mixed,实际上就是前两种模式的结合。在Mixed模式下,Mysql会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种。新版本中的Statment level还是和以前一样,仅仅记录执行的语句。而新版本的Mysql中队row level模式也被做了优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录,如果sql语句确实就是update或者delete等修改数据的语句,那么还是会记录所有行的变更。
01. mysqldump -u[user] -p[password] [databasename] > [dump_name] # 備份資料庫
02. /usr/local/mysql/bin/mysqladmin -u root -p shutdown # 停止資料庫
或是將整個 mysql tar 起來也可以。(不過還是建議用 mysqldump 的方式備份)
03. 建議將 InnoDB 中文參考手冊看過一次,這樣遇上問題,不會浪費太多時間在找答案。
InnoDB 中文參考手冊
http://www.twbb.org/ebook/MYSQL_INNDB_BIG5/
【例如:InnoDB 表不支持全文搜索(fulltext search),這樣我們就得
注意等等記得要將備份出來的資料庫,刪掉有關 Fulltext 的索引】
盡量看過,不然有先限制不知道的話,弄垮會浪費更多時間。
InnoDB 的限制
http://www.twbb.org/ebook/MYSQL_ ... InnoDB_restrictions
04. cd /usr/local/mysql/support-files/ 找尋適合主機記憶體的設定檔,必將設定檔拷貝到 /etc/my.cnf。
05. vi /etc/my.cnf ,將以下幾項註解取消掉。(以下為 my-large.cnf 的設定檔)
innodb_data_file_path = ibdata1:10M:autoextend
innodb_buffer_pool_size = 256M
innodb_additional_mem_pool_size = 20M
innodb_log_file_size = 5M
innodb_log_buffer_size = 8M
innodb_flush_log_at_trx_commit = 1
innodb_lock_wait_timeout = 50
加上 default-table-type=innodb
加上這段之後,以後新增的資料表型態都會是 InnoDB 囉,
不然每次新增一次資料表,SQL 後面得加上 Type=innodb;
避免麻煩,就先設定進去吧!但這個步驟不等於直接將MyISAM改
變成 InnoDB 型態喔!
當然啦!要用InnoDB當然得改成InnoDB的格式囉。^^"
06 .將剛剛備份出來的檔案,將Type=MyISAM改成Type=innodb。
07. /usr/local/mysql/bin/safe_mysqld --user=mysql & # 啟動資料庫
08. 建立一個新的資料庫(資料庫名稱跟備份出來的資料庫名稱一樣)。
09. mysql -u[user] -p[password] [database_name] < [dump_name] # 將改好的資料匯入資料庫中!
10. 做 Transaction 的測試,假如都沒問題,那就大公告成囉!
* 設定檔的選擇是參照記憶體大小來選擇。
my-huge.cnf - 1G~2G 、my-large.cnf - 512M 、
my-medium.cnf - 32M - 64M 、my-small.cnf <= 64M 。
InnoDB:my-innodb-heavy-4G.cnf
* 假如不會將備份出來的資料庫改型態,那麼您可以用下面這個指令,
直接改變資料表的型態。
ALTER TABLE [tablename] TYPE=InnoDB
如有存放全文索引功能的話,轉換會失敗喔!這點請各位要注意一下!
* 假若~你有一堆資料表要改,可以用下面的指令:
root# mysql_convert_table_format [opt] --type=InnoDB dbname [tablename]
但千萬注意!不要改變 mysql 資料庫的資料型態喔!因為 mysql
資料庫存放的是 MySQL 內部的管理資訊,所以必須保持 MyISAM 的格式。
* 加大 tablespace 空間:
innodb_data_file_path = ibdata1:1G;ibdata2:1G:autoextend:max2G
上面的意思是,tablespace 包含 ibdata1 & ibdata2 兩個檔案,
若檔案不存在,則建立容量各為1G的檔案。一旦未來 InnoDB 需要,
更多的空間,則 ibdata2 將每次自動增加 8MB,直到2G為止。
* MySQL 3.23.n,innodb_data_home & innodb_data_file_path
設定是必須要有的,MySQL 4.0.0 之後的版本則是非必須的。
使用mysqldump 备份数据库时,报错,错误信息如下:
mysqldump: Error: 'Got error 28 from storage engine' when trying to dump tablespaces
mysqldump: Couldn't execute 'show fields from `pre_common_addon`': Got error 28 from storage engine (1030)
使用计划任务备份时,总有这样的错误,而手动执行时,又很正常。
网上查找了些资料,猜测可能是因为磁盘空间不够导致的,但是一直想不通为什么手动执行又不抱错。最后研究了下备份脚本,发现问题所在,脚本的逻辑是,先备份,最后有一条命令就是删除创建日期大于1天的文件。其实问题就是在这里了,因为脚本备份时,磁盘空间已经不足了,因为我的表很大,十几个G,不够创建临时表的空间,导致不能备份完成,而最后执行删除创建日期大于1天的文件后,腾出空间,所以我手动执行又没有问题了。
解决办法:把脚本改动了一下,首先是删除旧文件,腾冲足够空间,然后再备份。这里还要注意的是,如果是找创建日期大于一天的文件,用-mtime +1 是不对的,要使用 -mmin +1200 (大于20小时),至于为什么,你自己想想吧。

新一代MySQL产品---MySQL5.5 已经面世,较之之前的5.1版本,将获得诸多特性方面的提升,简单总结如下:
1. 默认存储引擎更改为InnoDB
InnoDB作为成熟、高效的事务引擎,目前已经广泛使用,但MySQL5.1之前的版本默认引擎均为MyISAM,此次MySQL5.5终于 做到与时俱进,将默认数据库存储引擎改为InnoDB,并且引进了Innodb plugin 1.0.7。此次更新对数据库的好处是显而易见的:InnoDB的数据恢复时间从过去的一个甚至几个小时,缩短到几分钟(InnoDB plugin 1.0.7,InnoDB plugin 1.1, 恢复时采用红-黑树)。InnoDB Plugin 支持数据压缩存储,节约存储,提高内存命中率,并且支持adaptive flush checkpoint, 可以在某些场合避免数据库出现突发性能瓶颈。
Multi Rollback Segments: 原来InnoDB只有一个Segment,同时只支持1023的并发。现已扩充到128个Segments,从而解决了高并发的限制。
2. 多核性能提升
Metadata Locking (MDL) Framework替换LOCK_open mutex (lock),使得MySQL5.1及过去版本在多核心处理器上的性能瓶颈得到解决,官方表示将继续增强对MySQL多处理器支持,直至MySQL性能 “不受处理器数量的限制”
3. 复制功能(Replication)加强
MySQL复制特性是互联网公司应用非常广泛的特性,作为MySQL最实用最简单的扩展方式,过去的异步复制方式已经有些不上形势,对某些用户 来说“异步复制”意味着极端情况下的数据风险,MySQL5.5将首次支持半同步(semi-sync replication)在MySQL的高可用方案中将产生更多更加可靠的方案。另外Slave fsync tunning;Relay log corruption recovery和Replication Heartbeat也将实现
4. 增强表分区功能
MySQL 5.5的分区对用户绝对是个好消息,更易于使用的增强功能,以及TRUNCATE PARTITION命令都可以为DBA节省大量的时间,有时对最终用户亦如此:
1) 非整数列分区:任何使用过MySQL分区的人应该都遇到过不少问题,特别是面对非整数列分区时,MySQL 5.1只能处理整数列分区,如果你想在日期或字符串列上进行分区,你不得不使用函数对其进行转换。很麻烦,而MySQL 5.5中新增了两类分区方法,RANG和LIST分区法,同时在新的函数中增加了一个COLUMNS关键词。在MySQL 5.1中使用分区另一个让人头痛的问题是date类型(即日期列),你不能直接使用它们,必须使用YEAR或TO_DAYS转换这些列,但在MySQL 5.5中情况发生了很大的变化,现在在日期列上可以直接分区,并且方法也很简单;
2) 多列分区:COLUMNS关键字现在允许字符串和日期列作为分区定义列,同时还允许使用多个列定义一个分区;
3) 可用性增强:truncate分区。分区最吸引人的一个功能是瞬间移除大量记录的能力,DBA都喜欢将历史记录存储到按日期分区的分区表中,这样可以定期 删除过时的历史数据。 但当你需要移除分区中的部分数据时,事情就不是那么简单了,删除分区没有问题,但如果是清空分区,就很头痛了,要移除分区中的所有 数据,但需要保留分区本身,你可以:使用DELETE语句,但我们知道DELETE语句的性能都很差。使用DROP PARTITION语句,紧跟着一个EORGANIZE PARTITIONS语句重新创建分区,但这样做比前一个方法的成本要高出许多。MySQL 5.5引入了TRUNCATE PARTITION,它和DROP PARTITION语句有些类似,但它保留了分区本身,也就是说分区还可以重复利用。TRUNCATE PARTITION应该是DBA工具箱中的必备工具;
4) 更多微调功能:TO_SECONDS:分区增强包有一个新的函数处理DATE和DATETIME列,使用TO_SECONDS函数,你可以将日期/时间列转换成自0年以来的秒数,如果你想使用小于1天的间隔进行分区,那么这个函数就可以帮到你。
5. Insert Buffering 如果在buffer pool中没找到数据,那么直接buffer起来,避免额外的IO;Delete & Purge Buffering 跟插入一样,如果buffer pool中没有命中,先buffer起来,避免额外的IO。
6. Support for Native AIO on Linux
以上的特性在MySQL 5.5的社区版当中都将包括,在MySQL企业版当中,除以上更新之外,Oracle还加强了更多实用的企业级功能,包括:
1. 实现在线物理热备
MySQL 企业版将包含Innodb Hotbackup(这也许是MySQL和InnDB多年之后重新聚首的新亮点),从而一举解决过去MySQL无法进行可靠的在线实时物理备份的问题, InnoDB Hot Backup 不需要你关闭你的服务器也不需要加任何锁或影响其它普通的数据操作,这对MySQL DBA来说应该是一个不错的消息。
2. MySQL Enterprise Monitor 2.2 & Oracle Enterprise Monitor
是的,你没有看错,MySQL将可以被Oracle Enterprise Monitor监控,这是一个实现起来并不复杂,但在过去绝无可能的变化。并且MySQL企业版监控器(MySQL Enterprise Monitor)得到了更大的加强,版本更新至2.2,对MySQL服务器资源占用降低到可以忽略的地步,集成了监控,报警,SQL语句分析和给出优化建 议,MySQL的一些开源监控方案相比之下显得过于简陋,对企业客户来说,MySQL变得更加可靠。
3. MySQL Workbench
过去MySQL的图形界面工具做的实在是令人难以恭维,当然这也给众多MySQL管理工具提供了市场空间,现在Oracle打算将MySQL做 得比SQL-Server更加简单易用,MySQL Workbench是一款专为MySQL设计的ER/数据库建模工具,可以用来设计和创建新的数据库图示,建立数据库文档,以及进行复杂的MySQL 迁移等操作,因此内置workbench将使MySQL使用起来更简便高效。
4. 关于未来的重要提醒:Oracle的管理工具,MySQL也将能够使用,当然MySQL 5.5我们还没看到这个变化,但变化已经在时间表上,MySQL社区版也能够被Oracle管理工具管理,前提你得是Oracle数据库的用户。
备份:
mysqldump -u user -ppp db gk_info > Z:\gbinfo.sql
tab1 tab2 >
恢复:
mysql -u root -ppp --default-character-set=utf8 catalog < E:\work\dbupdate\gbinfo.sql
参考:
1.拷备文件 : (保证数据库没有写操作(可以给表上锁定))直接拷贝文件不能移植到其它机器上,除非你正在拷贝的表使用MyISAM存储格式
2.mysqldump : mysqldump生成能够移植到其它机器的文本文件
例:
备份整个数据库 --> mysqldump db1 >/backup/db1.20060725
压缩备份 --> mysqldump db1 | gzip >/backup/db1.20060725
分表备份 --> mysqldump db1 tab1 tab2 >/backup/db1_tab1_tab2.sql
直接远程备份 --> mysqladmin -h boa.snake.net create db1
--> mysqldump db1 | mysql -h boa.snake.net db1
复制备份表 --> cp tab.* backup/
恢复
用最新的备份文件重装数据库。如果你用mysqldump产生的文件,将它作为mysql的输入。如果你用直接从数据库拷贝来的文件,将它们直接拷回数据库目录,然而,此时你需要在拷贝文件之前关闭数据库,然后重启它。
一般我们平时安装MySQL都是源码包安装的,但是由于它的编译需要很长的时间,所以,我们公司的工程师都建议我们安装二进制免编译包。你可以到MySQL官方网站去下载,也可以到comsenz官方网站下载,下载地址为:http://syslab.comsenz.com/downloads/linux/ 。
下载下来以后,你要做的几步为:
1 解压 tar zxvf mysql-5.0.77-linux-x86_64-icc-glibc23.tar.gz
2 把解压完的数据放到合适的位置 mv mysql-5.0.77-linux-x86_64-icc-glibc23 /usr/local/
3 做一个软链接,这样做的目的是方便日后升级 ln -s /usr/local/mysql-5.0.77-linux-x86_64-icc-glibc23 /usr/local/mysql
4 建立mysql用户 useradd mysql
5 初始化数据库 cd /usr/local/mysql/ ; ./scripts/mysql_install_db --user=mysql //初始化库的时候可以只加一个--user,另外要想指定data目录的话,需要加上 --datadir= 这个参数,如,我想让数据库目录在 /home/mysql 下,则要这样 ./scripts/mysql_install_db --user=mysql --datadir=/home/mysql
6 拷贝配置文件 cp support-files/my-large.cnf /etc/my.cnf
7 拷贝启动脚本文件 cp support-files/mysql.server /etc/init.d/mysqld
8 修改权限 chmod 755 /etc/init.d/mysqld
9 修改启动脚本 vim /etc/init.d/mysqld //如果在初始话的时候指定了datadir,则要修改这个文件中的datadir部分,否则启动不了
10 启动MySQL /etc/init.d/mysqld start
InnoDB Plugin较之Built-in版本新增了很多特性:包括快速DDL、压缩存储等,而且引入了全新的文件格式Barracuda。众多测试也表明,Plugin在很多方面优于Built-in版本。当前Plugin版本是1.0.6,一个RC版本。MySQL的官方版本中从5.1.42开始也内置了InnoDB Plugin1.0.6。
innodb 不断更新的版本带来了一些有用的特性, 我们可以通过innodb plugin来在现有mysql版本(5.1.x)中更新innodb的版本, 从而可以在避免进行mysql整体升级的前提下使用上需要的功能。
下面以二进制分发版本(5.1.41)为例,说明下升级步骤(适用于5.1.38以上版本,以下版本需要下载innodb版本并替换目录):
1. 修改my.cnf 配置文件,临时注销所有innodb选项。
添加选项
ignore_builtin_innodb #忽略InnoDB built-in
2. 重启mysql 使ignore_builtin_innodb选项生效
3. 使用mysql管理帐号登录进行插件安装
INSTALL PLUGIN INNODB SONAME 'ha_innodb_plugin.so';
INSTALL PLUGIN INNODB_TRX SONAME 'ha_innodb_plugin.so';
INSTALL PLUGIN INNODB_LOCKS SONAME 'ha_innodb_plugin.so';
INSTALL PLUGIN INNODB_LOCK_WAITS SONAME 'ha_innodb_plugin.so';
INSTALL PLUGIN INNODB_CMP SONAME 'ha_innodb_plugin.so';
INSTALL PLUGIN INNODB_CMP_RESET SONAME 'ha_innodb_plugin.so';
INSTALL PLUGIN INNODB_CMPMEM SONAME 'ha_innodb_plugin.so';
INSTALL PLUGIN INNODB_CMPMEM_RESET SONAME 'ha_innodb_plugin.so'
4.查看版本select @@innodb_version;
+------------------+
| @@innodb_version |
+------------------+
| 1.0.5 |
+------------------+
5. 修改my.cnf配置文件,打开先前注释的innodb选项
如果需要使用barracuda可使用以下选项
innodb_file_format=barracuda 使用barracuda文件格式
innodb_file_per_table=1 使用barracuda文件格式需要采用单独表空间分配模式
6. 重启mysql
7. 检查日志确认确认是否存在异常
可能会发现如下新增信息
InnoDB: The InnoDB memory heap is disabled [如果采用系统内存分配默认会出现此信息,如果采用其他内存分配可以设置innodb_use_sys_malloc=0来使用指定内存,比如tcmalloc];
InnoDB: Mutexes and rw_locks use GCC atomic builtins [如果你使用的GCC版本高于4.12,那么互斥量(mutex)和读写锁(read/write lock)可以通过GCC内置的atomic_memory_access功能来实现,并打印这些信息]
110114 17:37:26 InnoDB: highest supported file format is Barracuda. [支持了Barracuda文件格式]
至此innodb plugin 升级完成。
这里列出一些有吸引力的特性
1. Barracuda 的compressed表自动对长的数据格式进行压缩 (比如blob,text,vachar等) 还可以指定压缩比
语句如下
alter table roberttest ROW_FORMAT=Compressed KEY_BLOCK_SIZE=8;
2. 添加辅助索引,不需要再通过建立临时表来进行过渡,提升了效率。
具体步骤为
(摘自mysql手册:InnoDB Pluing在删除一个secondary indexes时,先更改一下InnoDB内部数据字典和MySQL的数据字典,然后把释放的空间归还给InnoDB以供重复使用。如果是增加一个secondary indexes,还是有点复杂的,Plugin先将数据表中的数据取出到memory buffers或者临时表中,并按照新建索引列排好序,然后建立索引的B-Tree。 )
3. 对多核CPU和大内存提供更好的支持
另外 一篇 MySQL 5.1.24rc + innodb plugin尝鲜
1. mysql -uroot -ppassword
2. mysql> UPDATE mysql.user SET password=PASSWORD("newpwd") WHERE user='username' ; FLUSH PRIVILEGES;
#/bin/bash
DATE=`date +%Y-%m-%d`
MYSQL="mysql -uroot -h xxx "
for db in `$MYSQL -e "show databases"|sed '1d'`; do
mkdir -p $db_$DATE
cd $db_$DATE
for table in `$MYSQL $db -e "show tables"|sed '1d'`;do
mysqldump --opt $db $table |gzip >$db_$table.sql.gz
done
done
本帖最后由 lqph3387 于 2010-12-9 09:12 编辑
一,环境如下:
1、MySQL Proxy 安装地址:192.168.1.210 (简称A)
2、MySQL 主服务器地址:192.168.1.212(简称B)
3、MySQL 从服务器地址192.168.1.216(简称C)
如果目前B和C是Master-Slave模式(可以先在C上停止STOP SLAVE,不然等会在过程中我们往主库写数据的时候无法区分究竟是写到B还是C了,因为即使写到B机器上,我们在C机器上也能看到,因为通过replaction已经同步到C了,停掉slave的话,这样SQL语句一下子就看出来从哪里来的,让看众觉得有点啰嗦了

)
二,安装
下载已经编译好的安装包,或者预编译安装包均可,在这里,使用预编译版本
[root@ns ~]# tar zxf mysql-proxy-0.6.0-linux-rhas4-x86.tar.gz
[root@ns ~]# cd mysql-proxy-0.6.0-linux-rhas4-x86
#可以看到有2个目录
[root@ns mysql-proxy-0.6.0-linux-rhas4-x86]# ls
sbin share
[root@ns mysql-proxy-0.6.0-linux-rhas4-x86]# mv sbin/mysql-proxy /usr/local/sbin/
[root@ns mysql-proxy-0.6.0-linux-rhas4-x86]# ls share
mysql-proxy tutorial-constants.lua tutorial-packets.lua tutorial-rewrite.lua tutorial-warnings.lua
tutorial-basic.lua tutorial-inject.lua tutorial-query-time.lua tutorial-states.lua
#将lua脚本放到/usr/local/share下,以供启动脚本使用
[root@ns mysql-proxy-0.6.0-linux-rhas4-x86]# mv share/mysql-proxy /usr/local/share/
[root@ns mysql-proxy-0.6.0-linux-rhas4-x86]# strip /usr/local/sbin/mysql-proxy
三. 启动
编辑一下启动管理脚本:
[root@ns ~]# vim /etc/init.d/mysql-proxy
#!/bin/sh
export LUA_PATH=/usr/local/share/mysql-proxy/?.lua
mode=$1
if [ -z "$mode" ] ; then
mode="start"
fi
case $mode in
'start')
mysql-proxy --daemon \
--admin-address=192.168.1.210:4401 \
--proxy-address=192.168.1.210:3307 \
--proxy-backend-addresses=192.168.1.212:3306 \ 主库
--proxy-read-only-backend-addresses=192.168.1.216:3306 \ 从库
--proxy-lua-script=/usr/local/share/mysql-proxy/rw-splitting.lua
#限制192.168.1.212为可写,192.168.1.216为只读
;;
'stop')
killall mysql-proxy
;;
'restart')
if $0 stop ; then
$0 start
else
echo "retart failed!!!"
exit 1
fi
;;
esac
exit 0
解释一下启动脚本:
--daemon 采用daemon方式启动
--admin-address=192.168.1.210:4401 指定mysql proxy的管理端口,在这里,表示本机的4401端口
--proxy-address=192.168.1.210:3307 指定mysql proxy的监听端口,也可以用 127.0.0.1:3307 表示
--proxy-backend-addresses=192.168.1.212:3306 指定写库mysql主机的端口
--proxy-read-only-backend-addresses=192.168.1.216:3306 指定只读的mysql主机端口
--proxy-lua-script=/usr/local/share/mysql-proxy/rw-splitting.lua 指定lua脚本,在这里,使用的是rw-splitting脚本,用于读写分离
想查看完整的mysql-proxy 参数可以运行以下命令查看:mysql-proxy --help-all
运行以下命令启动/停止/重启mysql proxy:
[root@ns ~]# /etc/init.d/mysql-proxy start
[root@ns ~]# /etc/init.d/mysql-proxy stop
[root@ns ~]# /etc/init.d/mysql-proxy restart
四,使用MySQL Proxy
分别在192.168.1.212和192.168.1.216上安装mysql数据库,启动并添加一个用户
mysql>grant all privileges on test.* to abc@'%' identified by '123456';
在192.168.1.212的test数据库建立一个表hr
create table hr(id int(5),address char(255));
在192.168.1.216的test数据库建立一个表hr
create table hr(id int(5),name char(255));
两个表名字一样却有不同的字段。
在192.168.1.210上启动mysql-proxy
/etc/init.d/mysql-proxy start
[root@ns ~]# mysql -uabc -p123456 -h192.168.1.210 -P3307 test
对表进行查询
mysql> desc hr;
出现的表描述是C上的结构就对了。
对数据进行写操作
mysql> create table hr_boy(id int(5),name char(255));
然后去B上看看,如果B上多了一张表就对了
五,其他
mysql proxy还可以实现连接池的功能,因此,有了mysql proxy,就可以不用再担心连接数超限的问题了。
如果使用rw-splitting.lua脚本的话,最好修改以下2个参数的默认值:
min_idle_connections = 1
max_idle_connections = 3
修复数据表操作:
1、service mysqld stop;
2、cd /var/lib/mysql/db_name/
3、myisamchk -r tablename.MYI (修复单张数据表)
myisamchk -r *.MYI (修复所有数据表)
其实,在linux领域内大多用在服务器上,很少遇到关机的操作。毕竟服务器上跑一个服务是永无止境的,除非特殊情况下,不得已才会关机。
linux和windows不同,在 Linux 底下,由于每个程序(或者说是服务)都是在在背景下执行的,因此,在你看不到的屏幕背后其实可能有相当多人同时在你的主机上面工作,例如浏览网页啦、传送信件啦以 FTP 传送档案啦等等的,如果你直接按下电源开关来关机时,则其它人的数据可能就此中断!那可就伤脑筋了!此外,最大的问题是,若不正常关机,则可能造成文件系统的毁损(因为来不及将数据回写到档案中,所以有些服务的档案会有问题!)。
如果你要关机,必须要保证当前系统中没有其他用户在线。可以下达 who 这个指令,而如果要看网络的联机状态,可以下达 netstat -a 这个指令,而要看背景执行的程序可以执行 ps -aux 这个指令。使用这些指令可以让你稍微了解主机目前的使用状态!(这些命令在以后的章节中会提及,现在只要了解即可!)
正确的关机流程为:sysnc --> shutdown --> reboot --> halt
sync 将数据由内存同步到硬盘中。
shutdown 关机指令,你可以man shutdown 来看一下帮助文档。例如你可以运行如下命令关机:
shutdown –h 10 ‘This server will shutdown after 10 mins’ 这个命令告诉大家,计算机将在10分钟后关机,并且会显示在登陆用户的当前屏幕中。
shutdown –h now 立马关机
shutdown –h 20:25 系统会在今天20:25关机
shutdown –h +10 十分钟后关机
shutdown –r now 系统立马重启
shutdown –r +10 系统十分钟后重启
reboot 就是重启,等同于 shutdown –r now
halt 关闭系统,等同于shutdown –h now 和 poweroff
最后总结一下,不管是重启系统还是关闭系统,首先要运行sync命令,把内存中的数据写到磁盘中。关机的命令有 shutdown –h now halt poweroff 和 init 0 , 重启系统的命令有 shutdown –r now reboot init 6.
下一章
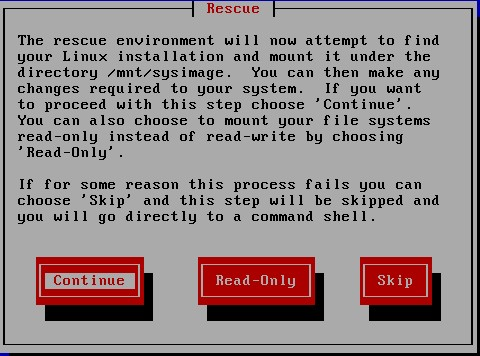
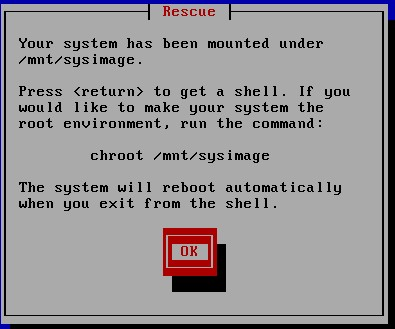
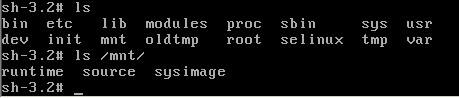
忘记root密码如何做
- «
- 1
- ...
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- ...
- 68
- »