rsync常用选项
-a:归档模式,表示以递归方式传输文件,并保持所有属性,等同于-rlptgoD ,-a选项后面可以跟一个 --no-OPTION 这个表示关闭-rlptgoD中的某一个例如 -a --no-l 等同于-rptgoD
-r :对子目录以递归模式处理,主要是针对目录来说的,如果单独传一个文件不需要加-r,但是传输的是目录必须加-r选项
-v :打印一些信息出来,比如速率,文件数量等
-l :保留软链结
-L :向对待常规文件一样处理软链结,如果是SRC中有软连接文件,则加上该选项后将会把软连接指向的目标文件拷贝到DST
-p :保持文件权限
-o :保持文件属主信息
-g :保持文件属组信息
-D :保持设备文件信息
-t :保持文件时间信息
--delete :删除那些DST中SRC没有的文件
--exclude=PATTERN
:指定排除不需要传输的文件,等号后面跟文件名,可以是万用字符模式(如*.txt)
-u :加上这个选项后将会把DST中比SRC还新的文件排除掉,不会覆盖
下面笔者将会针对这些选项做一些列小实验:
1)
建立目录以及文件
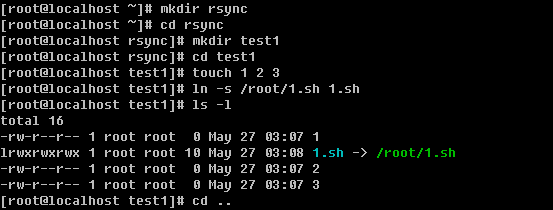
笔者建立这些文件的目的就是为做试验做一些准备工作。
2)使用-a选项

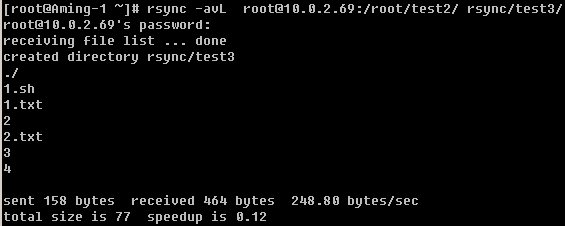
这里有一个问题,就是本来想把test1目录直接拷贝成test2目录,可结果rsync却新建了test2目录然后把test1放到test2当中。为了避免这样的情况发生,可以这样做:

加一个斜杠就好了,所以笔者建议你在使用rsync备份目录时要养成加斜杠的习惯。在上面讲了-a选项等同于- rlptgoD,而且-a还可以和--no-OPTION一并使用。
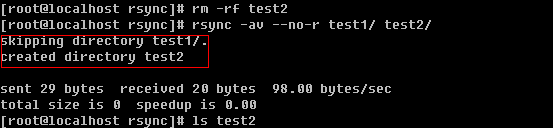
笔者加上-v选项来获得更多的信息,上例中因为没有使用-r选项导致只能拷贝目录但不能拷贝目录下面的内容(英文翻译过来就是“忽略了目录test1/.”,其中test1/.指的就是test1目录内部的所有文件),所以虽然创建了test2目录,但是test2目录为空。下面再看看那个-l选项的作用。
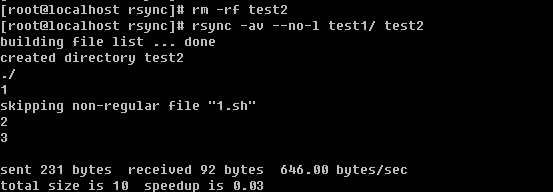
使用-v选项看来就是方便呀,上例告诉我们跳过了非普通文件1.sh,其实1.sh是一个软连接文件,如果不使用-l选项则不会理会软连接文件的。

果真test2目录当中没有那个1.sh的影子。当然加上-l选项则会把软连接文件给拷贝过去,但是软连接的目标文件却没有拷贝过去,有时候咱们指向拷贝软连接文件所指向的目标文件,那这时候该怎么办呢?
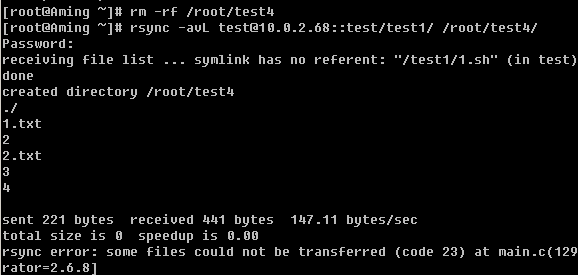
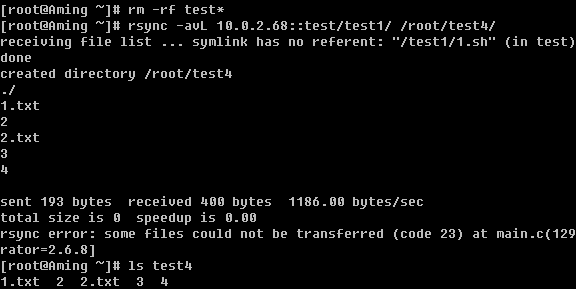
3)使用-L选项
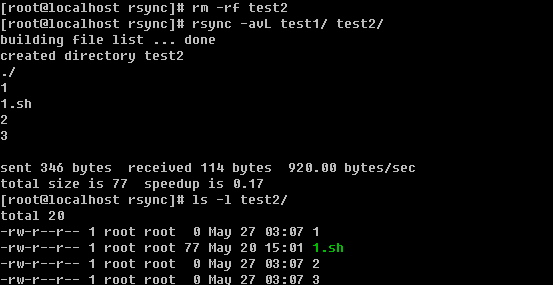
一个-L就可以把SRC中软连接的目标文件给拷贝到DST
4)
使用-u选项
首先查看一下test1/1 和 test2/1的访问时间(肯定是一样的),然后使用touch修改一下test2/1的访问时间(此时test2/1要比test1/1的访问时间晚了一些),如果不加-u选项的话,会把test2/1的访问时间变成和test1/1的访问时间一样。这样讲也许你会迷糊,不妨看一看。
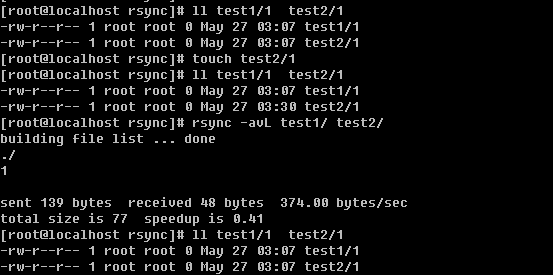
看到了吧,本来test2/1的访问时间已经不同于test1/1的访问时间了,但是同步后访问时间又一致了。
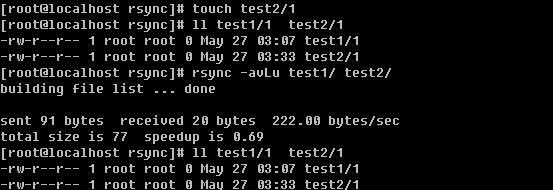
现在你明白-u选项的妙用了吧。
5)使用--delete选项
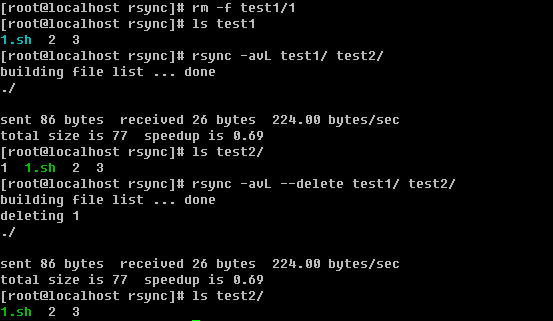
如果不使用--delete选项当SRC有文件删除时,DST是不会删除的,只有加上--delete选项后才能删除掉。还有一种情况就是如果在DST增加文件了,而SRC当中没有这些文件,同步时加上--delete选项后同样会删除新增的文件。
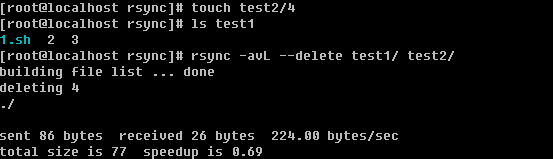
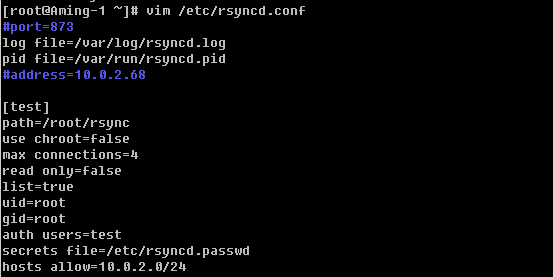
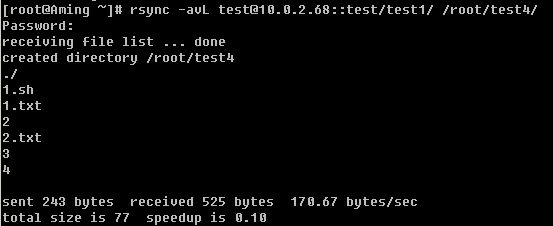
6)使用--exclude 选项
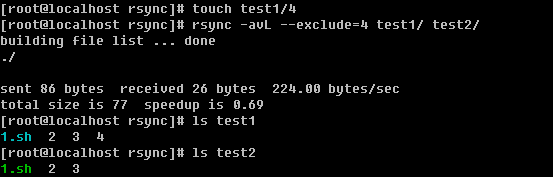
另外还可以使用万用字符*匹配
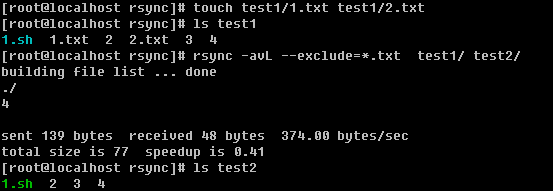
最后简单总结一下,平时你使用rsync同步数据的时候,使用-a选项基本上就可以达到我们想要的效果了,只是有时候会有个别的需求,会用到-a --no-OPTION, -u, -L, --delete, --exclude这些选项,但是笔者要求你把上面这些全部掌握,毕竟这才几个而已,大部分选项笔者都没有介绍。如果在以后的工作中遇到特殊需求了,就去查一下rsync的man文档吧。
none





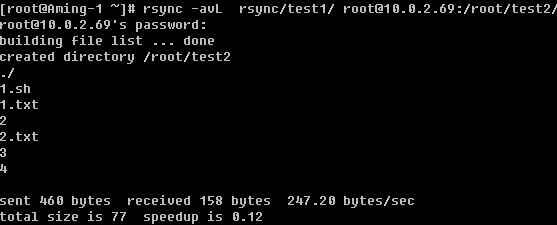













 中的’localhost’更改成’Aming’。不过这样修改只是保存在内存中,下次重启还会变成未改之前的主机名,所以需要你还要去更改相关的配置文件’/etc/sysconfig/network’。
中的’localhost’更改成’Aming’。不过这样修改只是保存在内存中,下次重启还会变成未改之前的主机名,所以需要你还要去更改相关的配置文件’/etc/sysconfig/network’。