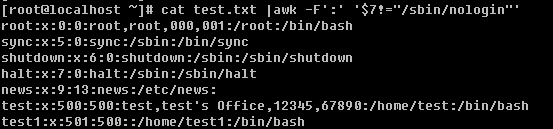
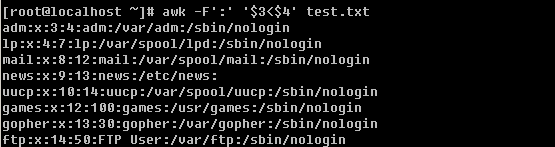
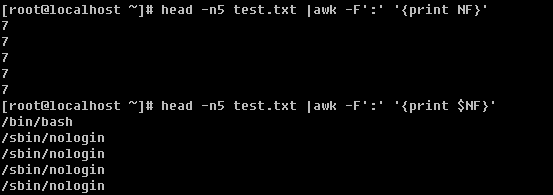
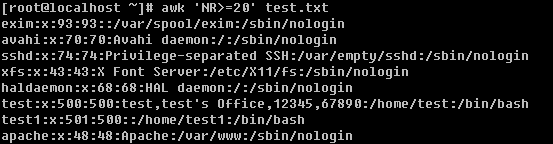
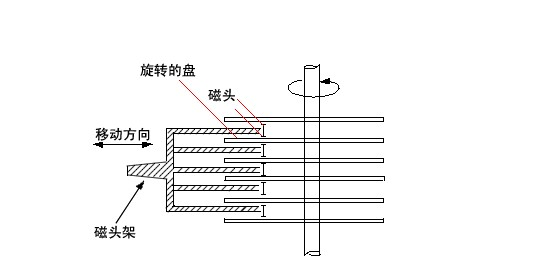
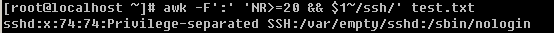在讲连接档之前,需要你先理解inode的概念。什么是inode呢?这就需要你知道磁盘的整体构造。磁盘是有多个盘片(类似与光盘)重叠在一起构成的,而每个盘片上会有一个可以移动的磁头,这个磁头的作用就是用来读写数据的。磁头并不是一直在动,当磁头固定时,盘片转一圈,这一圈就是一个磁道了。很多个盘片同半径的那一圈的磁道总和称为磁柱。而由圆心向外画出直线,可以得到一个个扇区,如图二所示,一个扇区的物理量大约是 512 bytes ( 约 0.5K )。
图一

图二
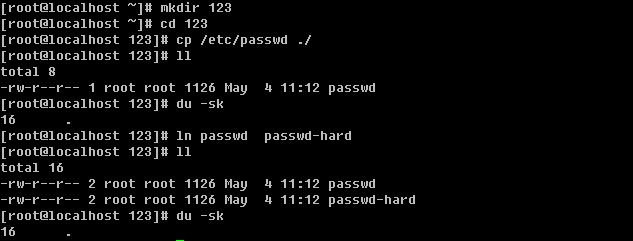
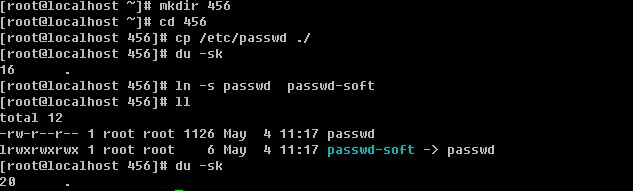
知道了大体的硬盘构造之后,再来谈一谈怎么硬盘分割( partition )呢?我们在进行硬盘分割的时候,最小都是以磁柱为单位进行分割的,那么分割完成之后自然就是格式化( format )啰,在 Linux 里面我们在进行格式化的时候必须要考虑到 Block 与 inode 的信息,这个 block 还好理解,他是我们磁盘可以记录的最小单位,是由数个 sector 所组成的,所以他的大小通常为 n*512 bytes ,例如 4K 。那么 inode 是什么? Block 是记录“档案内容数据”的地区,而 inode 则是记录“该档案的属性、及该档案放置在哪一个 Block 之内”的信息!所以,每个档案都会占用到至少一个 inode 。而当我们 Linux 系统要找到这个档案时,他会先去搜寻 inode table 找到这个档案的属性及数据放置的地区,然后再到数据去找到数据存放的 Block 进而将数据取出利用。这个 inode 数目在一开始就会被设定好,他的设定方式通常是利用 ( 硬盘大小 / 一个容量 ),这个容量至少应该比 Block 要大一些较佳,例如刚刚的 Block 订为 4K ,那么 inode 可以订为 8K 左右。所以,一颗 1GB 的硬盘,如果以 8K 来规划他的 inode 数时,他的 inode 就会有 131072 个 inode 啦!而一个 inode 的大小为 128 bytes 这么大!这么一来的话,我们就可以清楚的知道了,那就是一个 partition 格式化为一个 filesystem 之后,基本上,他一定会有 inode table 与 data area 两个区块,一个用来记录档案的信息与该档案放置的 block 区块,一个用来记录档案的内容!
由于我们 Linux 在读取数据的时候,是先查询 inode table 以得到数据是放在那个 Block 里面,然后再去该 Block 里面读取真正的数据内容!然后,那个 block 是我们在格式化硬盘的时候规定出来的一个值,这个 block 是由 2 的 n 次方个sector 所集结而成的!所以,他是 0.5K 的倍数!假设我们 block 规划为 4KBytes 好了,那么由于一个 inode 与一个block 最多均只纪录一个档案,所以,如果你的一个档案有 0.1 K bytes 这么大时,你要晓得的是,由于你的 block 为 4K bytes ,因此,你就会有 3.9 Kbytes 的空间浪费掉!所以,当你在格式化硬盘的时候,请千万注意到你的系统未来的使用方向。
none
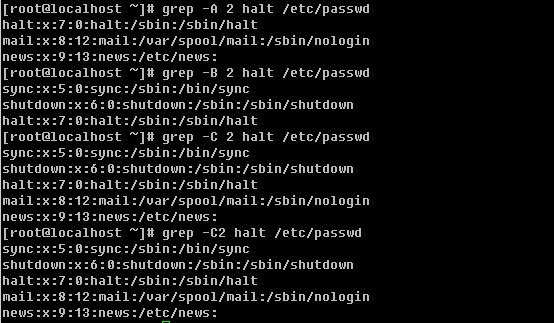
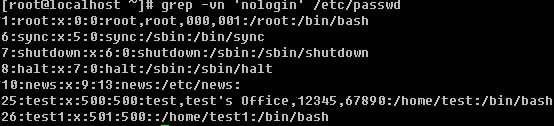
grep 工具的功能其实还不够强大,其实说白了,grep实现的只是查找功能,而它却不能实现把查找的内容替换掉。以前用vim的时候,可以查找也可以替换,但是只局限于在文本内部来操作,而不能输出到屏幕上。sed工具以及下面要讲的awk工具就能实现把替换的文本输出到屏幕上的功能了,而且还有其他更丰富的功能。sed和awk都是流式编辑器,是针对文档的行来操作的。
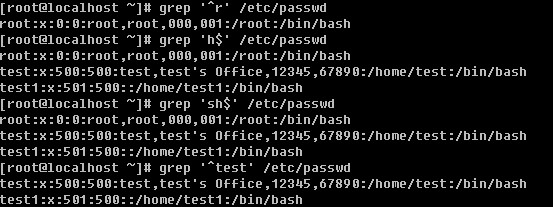
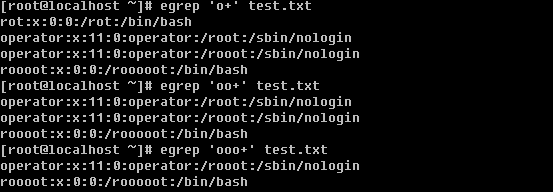
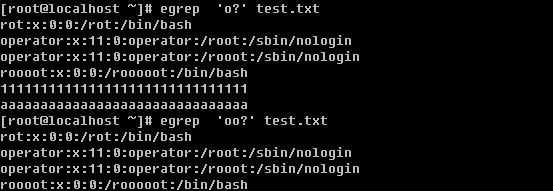
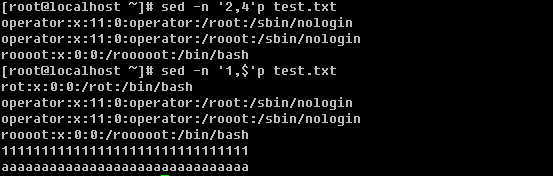
a. 打印某行 sed -n ‘n’p filename 单引号内的n是一个数字,表示第几行

b. 打印多行
打印整个文档用 -n ‘1,$’p
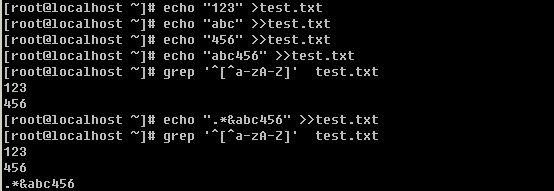
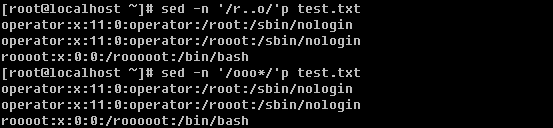
c. 打印包含某个字符串的行

上面grep中使用的特殊字符,如’^’, ‘$’, ‘.’, ‘*’等同样也能在sed中使用。

d. -e 可以实现多个行为

e. 删除某行或者多行
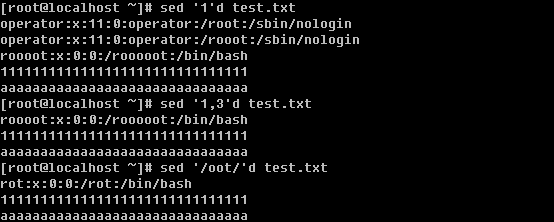
‘d’ 这个字符就是删除的动作了,不仅可以删除指定的单行以及多行,而且还可以删除匹配某个字符的行,另外还可以删除从某一行一直到文档末行。

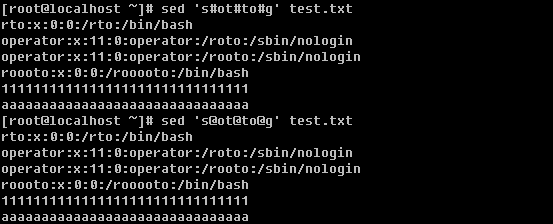
f. 替换字符或字符串

上例中的’s’就是替换的命令,’g’为本行中全局替换,如果不加’g’,只换该行中出现的第一个。
除了可以使用’/’外,还可以使用其他特殊字符例如’#’或者[email=’@’]’@’[/email]都没有问题。
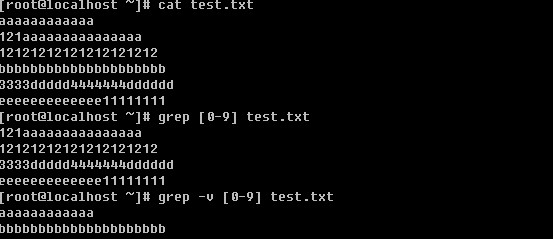
现在思考一下,如何删除文档中的所有数字或者字母?
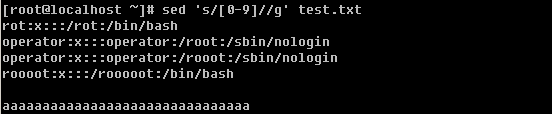
有意思吧,[0-9]表示任意的数字。这里你也可以写成[a-zA-Z]甚至[0-9a-zA-Z]
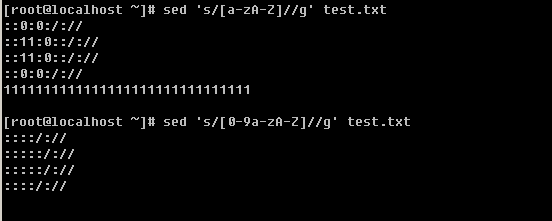
g. 调换两个字符串的位置
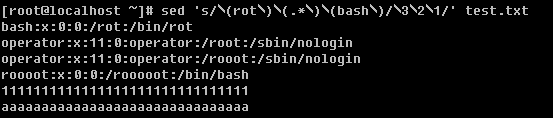
这个就需要解释一下了,上例中用’()’把所想要替换的字符括起来成为一个整体,因为括号在sed中属于特殊符号,所以需要在前面加脱意字符’\’,替换时则写成’\1’, ‘\2’, ‘\3’ 的形式。除了调换两个字符串的位置外,笔者还常常用到在某一行前或者后增加指定内容。
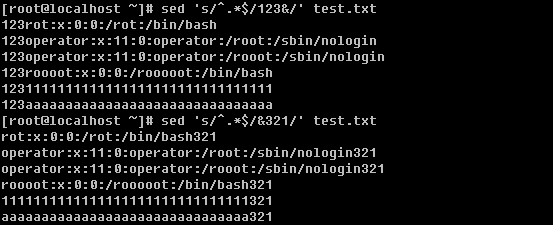
h. 直接修改文件的内容
sed -i ‘s/:/#/g’ test.txt ,这样就可以直接更改test.txt文件中的内容了。由于这个命令可以直接把文件修改,所以在修改前最好先复制一下文件以免改错。
sed常用到的也就上面这些了,只要你多加练习就能熟悉它了。为了能让你更加牢固的掌握sed的应用,笔者留几个练习题给你,希望你能认真完成。
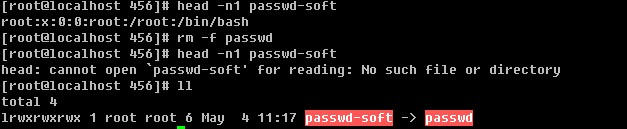
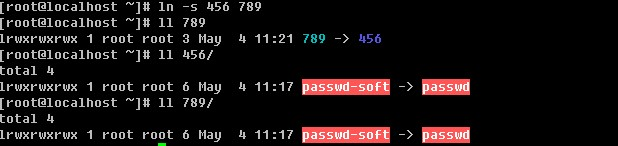
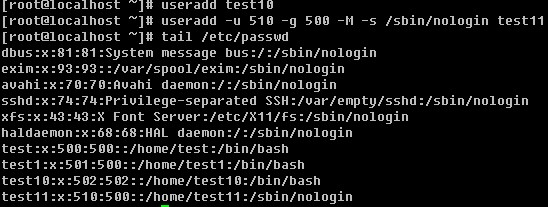
1. 把/etc/passwd 复制到/root/test.txt,用sed打印所有行;
2. 打印test.txt的3到10行;
3. 打印test.txt 中包含’root’的行;
4. 删除test.txt 的15行以及以后所有行;
5. 删除test.txt中包含’bash’的行;
6. 替换test.txt 中’root’为’toor’;
7. 替换test.txt中’/sbin/nologin’为’/bin/login’
8. 删除test.txt中5到10行中所有的数字;
9. 删除test.txt 中所有特殊字符(除了数字以及大小写字母);
10. 把test.txt中第一个单词和最后一个单词调换位置;
11. 把test.txt中出现的第一个数字和最后一个单词替换位置;
12. 把test.txt 中第一个数字移动到行末尾;
13. 在test.txt 20行到末行最前面加’aaa:’;
现在给出以上练习题的答案,你如果实在想不出如何操作,那你看看答案吧,请尽量多想一下。
1. /bin/cp /etc/passwd /root/test.txt ; sed -n '1,$'p test.txt
2. sed -n '3,10'p test.txt
3. sed -n '/root/'p test.txt
4. sed '15,$'d test.txt
5. sed '/bash/'d test.txt
6. sed 's/root/toor/g' test.txt
7. sed 's#sbin/nologin#bin/login#g' test.txt
8. sed '5,10s/[0-9]//g' test.txt
9. sed 's/[^0-9a-zA-Z]//g' test.txt
10. sed 's/\(^[a-zA-Z][a-zA-Z]*\)\([^a-zA-Z].*\)\([^a-zA-Z]\)\([a-zA-Z][a-zA-Z]*$\)/\4\2\3\1/' test.txt
11. sed 's#\([^0-9][^0-9]*\)\([0-9][0-9]*\)\([^0-9].*\)\([^a-zA-Z]\)\([a-zA-Z][a-zA-Z]*$\)#\1\5\3\4\2#' test.txt
12. sed 's#\([^0-9][^0-9]*\)\([0-9][0-9]*\)\([^0-9].*$\)#\1\3\2#' test.txt
13. sed '20,$s/^.*$/aaa:&/' test.txt
none
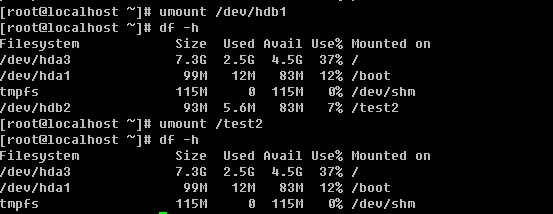
这两个文件可以说是linux系统中最重要的文件之一。如果没有这两个文件或者这两个文件出问题,则你是无法正常登录linux系统的。
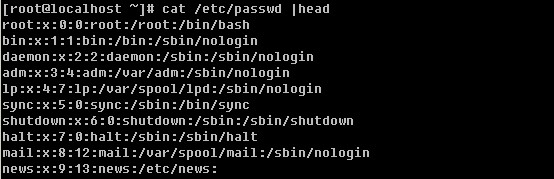 /etc/passwd由’:’分割成7个字段,每个字段的具体含义是:
1)用户名(如第一行中的root就是用户名),代表用户账号的字符串。用户名字符可以是大小写字母、数字、减号(不能出现在首位)、点以及下划线,其他字符不合法。虽然用户名中可以出现点,但不建议使用,尤其是首位为点时,另外减号也不建议使用,因为容易造成混淆。
2)存放的就是该账号的口令,为什么是’x’呢?早期的unix系统口令确实是存放在这里,但基于安全因素,后来就将其存放到/etc/shadow中了,在这里只用一个’x’代替。
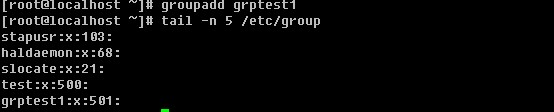
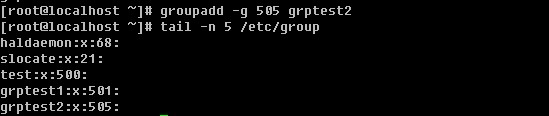
3)这个数字代表用户标识号,也叫做uid。系统识别用户身份就是通过这个数字来的,0就是root,也就是说你可以修改test用户的uid为0,那么系统会认为root和test为同一个账户。通常uid的取值范围是0~65535,0是超级用户(root)的标识号,1~499由系统保留,作为管理账号,普通用户的标识号从500开始,如果我们自定义建立一个普通用户,你会看到该账户的标识号是大于或等于500的。
4)表示组标识号,也叫做gid。这个字段对应着/etc/group 中的一条记录,其实/etc/group和/etc/passwd基本上类似。
5)注释说明,该字段没有实际意义,通常记录该用户的一些属性,例如姓名、电话、地址等等。不过,当你使用finger的功能时就会显示这些信息的(稍后做介绍)。
6)用户的家目录,当用户登录时就处在这个目录下。root的家目录是/root,普通用户的家目录则为/home/username,这个字段是可以自定义的,比如你建立一个普通用户test1,要想让test1的家目录在/data目录下,只要修改/etc/passwd文件中test1那行中的该字段为/data即可。
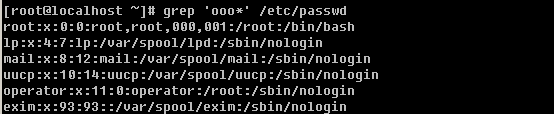
7)shell,用户登录后要启动一个进程,用来将用户下达的指令传给内核,这就是shell。Linux的shell有很多种sh, csh, ksh, tcsh, bash等,而Redhat/CentOS的shell就是bash。查看/etc/passwd文件,该字段中除了/bin/bash外还有/sbin/nologin比较多,它表示不允许该账号登录。如果你想建立一个账号不让他登录,那么就可以把该字段改成/sbin/nologin,默认是/bin/bash。
/etc/passwd由’:’分割成7个字段,每个字段的具体含义是:
1)用户名(如第一行中的root就是用户名),代表用户账号的字符串。用户名字符可以是大小写字母、数字、减号(不能出现在首位)、点以及下划线,其他字符不合法。虽然用户名中可以出现点,但不建议使用,尤其是首位为点时,另外减号也不建议使用,因为容易造成混淆。
2)存放的就是该账号的口令,为什么是’x’呢?早期的unix系统口令确实是存放在这里,但基于安全因素,后来就将其存放到/etc/shadow中了,在这里只用一个’x’代替。
3)这个数字代表用户标识号,也叫做uid。系统识别用户身份就是通过这个数字来的,0就是root,也就是说你可以修改test用户的uid为0,那么系统会认为root和test为同一个账户。通常uid的取值范围是0~65535,0是超级用户(root)的标识号,1~499由系统保留,作为管理账号,普通用户的标识号从500开始,如果我们自定义建立一个普通用户,你会看到该账户的标识号是大于或等于500的。
4)表示组标识号,也叫做gid。这个字段对应着/etc/group 中的一条记录,其实/etc/group和/etc/passwd基本上类似。
5)注释说明,该字段没有实际意义,通常记录该用户的一些属性,例如姓名、电话、地址等等。不过,当你使用finger的功能时就会显示这些信息的(稍后做介绍)。
6)用户的家目录,当用户登录时就处在这个目录下。root的家目录是/root,普通用户的家目录则为/home/username,这个字段是可以自定义的,比如你建立一个普通用户test1,要想让test1的家目录在/data目录下,只要修改/etc/passwd文件中test1那行中的该字段为/data即可。
7)shell,用户登录后要启动一个进程,用来将用户下达的指令传给内核,这就是shell。Linux的shell有很多种sh, csh, ksh, tcsh, bash等,而Redhat/CentOS的shell就是bash。查看/etc/passwd文件,该字段中除了/bin/bash外还有/sbin/nologin比较多,它表示不允许该账号登录。如果你想建立一个账号不让他登录,那么就可以把该字段改成/sbin/nologin,默认是/bin/bash。
 再来看看/etc/shadow这个文件,和/etc/passwd类似,用”:”分割成9个字段。
1)用户名,跟/etc/passwd对应。
2)用户密码,这个才是该账号的真正的密码,不过这个密码已经加密过了,但是有些黑客还是能够解密的。所以为了安全,该文件属性设置为600,只允许root读写。
3)上次更改密码的日期,这个数字是这样计算得来的,距离1970年1月1日到上次更改密码的日期,例如上次更改密码的日期为2012年1月1日,则这个值就是365*(2012-1970)+1=15331。
4)要过多少天才可以更改密码,默认是0,即不限制。
5)密码多少天后到期。即在多少天内必须更改密码,例如这里设置成30,则30天内必须更改一次密码,否则将不能登录系统,默认是99999,可以理解为永远不需要改。
6)密码到期前的警告期限,若这个值设置成7,则表示当7天后密码过期时,系统就发出警告告诉用户,提醒用户他的密码将在7天后到期。
7)账号失效期限。你可以这样理解,如果设置这个值为3,则表示:密码已经到期,然而用户并没有在到期前修改密码,那么再过3天,则这个账号就失效了,即锁定了。
8)账号的生命周期,跟第三段一样,是按距离1970年1月1日多少天算的。它表示的含义是,账号在这个日期前可以使用,到期后账号作废。
9)作为保留用的,没有什么意义。
再来看看/etc/shadow这个文件,和/etc/passwd类似,用”:”分割成9个字段。
1)用户名,跟/etc/passwd对应。
2)用户密码,这个才是该账号的真正的密码,不过这个密码已经加密过了,但是有些黑客还是能够解密的。所以为了安全,该文件属性设置为600,只允许root读写。
3)上次更改密码的日期,这个数字是这样计算得来的,距离1970年1月1日到上次更改密码的日期,例如上次更改密码的日期为2012年1月1日,则这个值就是365*(2012-1970)+1=15331。
4)要过多少天才可以更改密码,默认是0,即不限制。
5)密码多少天后到期。即在多少天内必须更改密码,例如这里设置成30,则30天内必须更改一次密码,否则将不能登录系统,默认是99999,可以理解为永远不需要改。
6)密码到期前的警告期限,若这个值设置成7,则表示当7天后密码过期时,系统就发出警告告诉用户,提醒用户他的密码将在7天后到期。
7)账号失效期限。你可以这样理解,如果设置这个值为3,则表示:密码已经到期,然而用户并没有在到期前修改密码,那么再过3天,则这个账号就失效了,即锁定了。
8)账号的生命周期,跟第三段一样,是按距离1970年1月1日多少天算的。它表示的含义是,账号在这个日期前可以使用,到期后账号作废。
9)作为保留用的,没有什么意义。
none
在windows下我们接触最多的压缩文件就是.rar格式的了。但在linux下这样的格式是不能识别的,它有自己所特有的压缩工具。但有一种文件在windows和linux下都能使用那就是.zip格式的文件了。压缩的好处不用笔者介绍相信你也晓得吧,它不仅能节省磁盘空间而且在传输的时候还能节省网络带宽呢。
在linux下最常见的压缩文件通常都是以.tar.gz 为结尾的,除此之外还有.tar, .gz, .bz2, .zip等等。以前也介绍过linux系统中的后缀名其实要不要无所谓,但是对于压缩文件来讲必须要带上。这是为了判断压缩文件是由哪种压缩工具所压缩,而后才能去正确的解压缩这个文件。以下介绍常见的后缀名所对应的压缩工具。
.gz gzip 压缩工具压缩的文件
.bz2 bzip2 压缩工具压缩的文件
.tar tar 打包程序打包的文件(tar并没有压缩功能,只是把一个目录合并成一个文件)
.tar.gz 可以理解为先用tar打包,然后再gzip压缩
.tar.bz2 同上,先用tar打包,然后再bzip2压缩
none
终于到shell 脚本这章了,在以前笔者卖了好多关子说shell脚本怎么怎么重要,确实shell脚本在linux系统管理员的运维工作中非常非常重要。下面笔者就带你正式进入shell脚本的世界吧。
到现在为止,你明白什么是shell脚本吗?如果明白最好了,不明白也没有关系,相信随着学习的深入你就会越来越了解到底什么是shell脚本。首先它是一个脚本,并不能作为正式的编程语言。因为是跑在linux的shell中,所以叫shell脚本。说白了,shell脚本就是一些命令的集合。举个例子,我想实现这样的操作:1)进入到/tmp/目录;2)列出当前目录中所有的文件名;3)把所有当前的文件拷贝到/root/目录下;4)删除当前目录下所有的文件。简单的4步在shell窗口中需要你敲4次命令,按4次回车。这样是不是很麻烦?当然这4步操作非常简单,如果是更加复杂的命令设置需要几十次操作呢?那样的话一次一次敲键盘会很麻烦。所以不妨把所有的操作都记录到一个文档中,然后去调用文档中的命令,这样一步操作就可以完成。其实这个文档呢就是shell脚本了,只是这个shell脚本有它特殊的格式。
Shell脚本能帮助我们很方便的去管理服务器,因为我们可以指定一个任务计划定时去执行某一个shell脚本实现我们想要需求。这对于linux系统管理员来说是一件非常值得自豪的事情。现在的139邮箱很好用,发邮件的同时还可以发一条邮件通知的短信给用户,利用这点,我们就可以在我们的linux服务器上部署监控的shell脚本,比如网卡流量有异常了或者服务器web服务器停止了就可以发一封邮件给管理员,同时发送给管理员一个报警短信这样可以让我们及时的知道服务器出问题了。
有一个问题需要约定一下,凡是自定义的脚本建议放到/usr/local/sbin/目录下,这样做的目的是,一来可以更好的管理文档;二来以后接管你的管理员都知道自定义脚本放在哪里,方便维护。
none
前面内容中提到了findger,即在/etc/passwd文件中的第5个字段中所显示的信息,那么如何去设定这个信息呢?
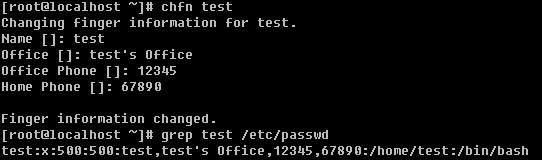 就是chfn这个命令了。修改完后,就会在/etc/passwd文件中的test的那一行第五个字段中看到相关信息了,默认是空的。
就是chfn这个命令了。修改完后,就会在/etc/passwd文件中的test的那一行第五个字段中看到相关信息了,默认是空的。
none
- «
- 1
- ...
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- »